
Introduction
Code sur Github: Enrichissement des données Elasticsearch
Si vous n'avez pas encore configuré Elasticsearch et Kibana, alors suivez ces instructions.
Cette vidéo suppose que vous utilisez Certificats signés publiquement. Si vous utilisez Certificats auto-signés, va ici À déterminer.
Exigences
- Une instance en cours d'exécution d'Elasticsearch et de Kibana.
- Une instance d’un autre serveur Ubuntu 20.04 exécutant n’importe quel type de service.
Processus
Définition de l'enrichissement des données [00:09]
Accédez à l'horodatage spécifique de la vidéo pour mieux comprendre ce que signifie l'enrichissement des données.
Comment enrichir les données en fonction de la « correspondance exacte » [05:47]
Étape 1 : Configuration d'un index source [06:22]
À Kibana, allez à Outils de développement > Console. Collez la commande ci-dessous dans la console, et lorsque vous exécutez cette commande, ce que fera Elasticsearch, c'est qu'il créera automatiquement un nouvel index et y ajoutera ces données, puis effectuera un mappage automatique pour chacun des champs.
PUT /users/_doc/1?refresh=wait_for
{
"email": "mardy.brown@asciidocsmith.com",
"first_name": "Mardy",
"last_name": "Brown",
"city": "New Orleans",
"county": "Orleans",
"state": "LA",
"zip": 70116,
"web": "mardy.asciidocsmith.com"
}
Après l'exécution, il devrait produire un résultat similaire à l'image ci-dessous ;
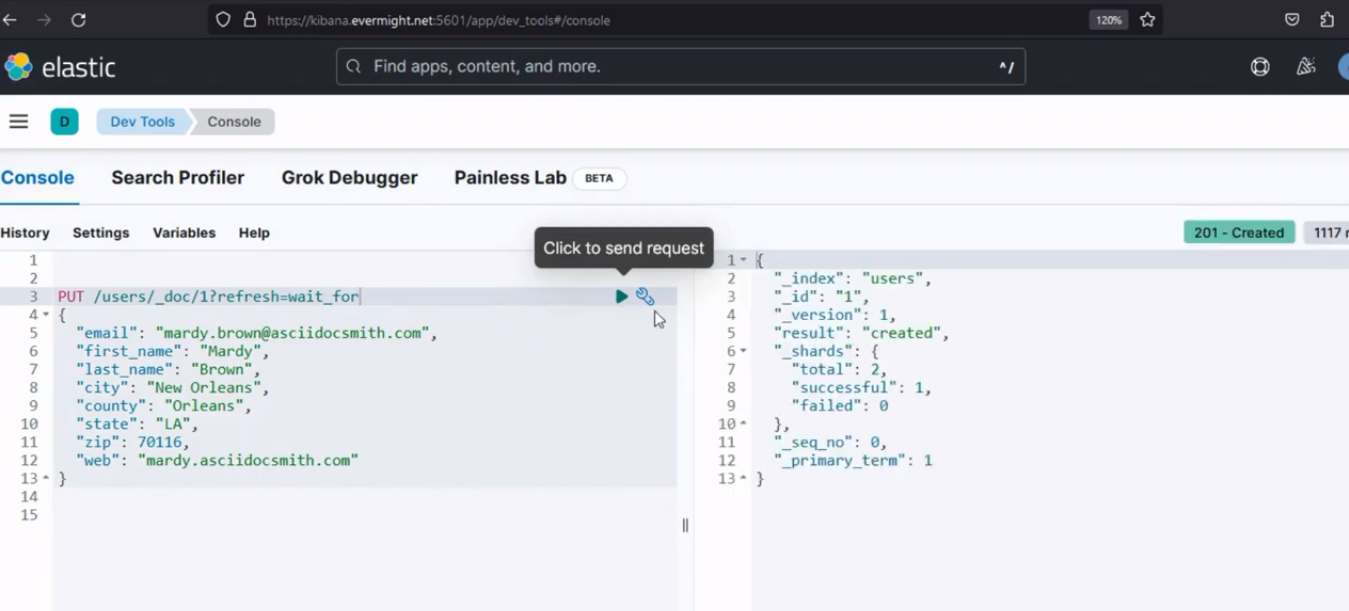 Résultat de la console pour l'étape 1
Résultat de la console pour l'étape 1
Pour confirmer que l'index a été créé avec succès, accédez à Gestion de la pile > Gestion des index. Et vous devriez voir un résultat similaire à l'image ci-dessous :
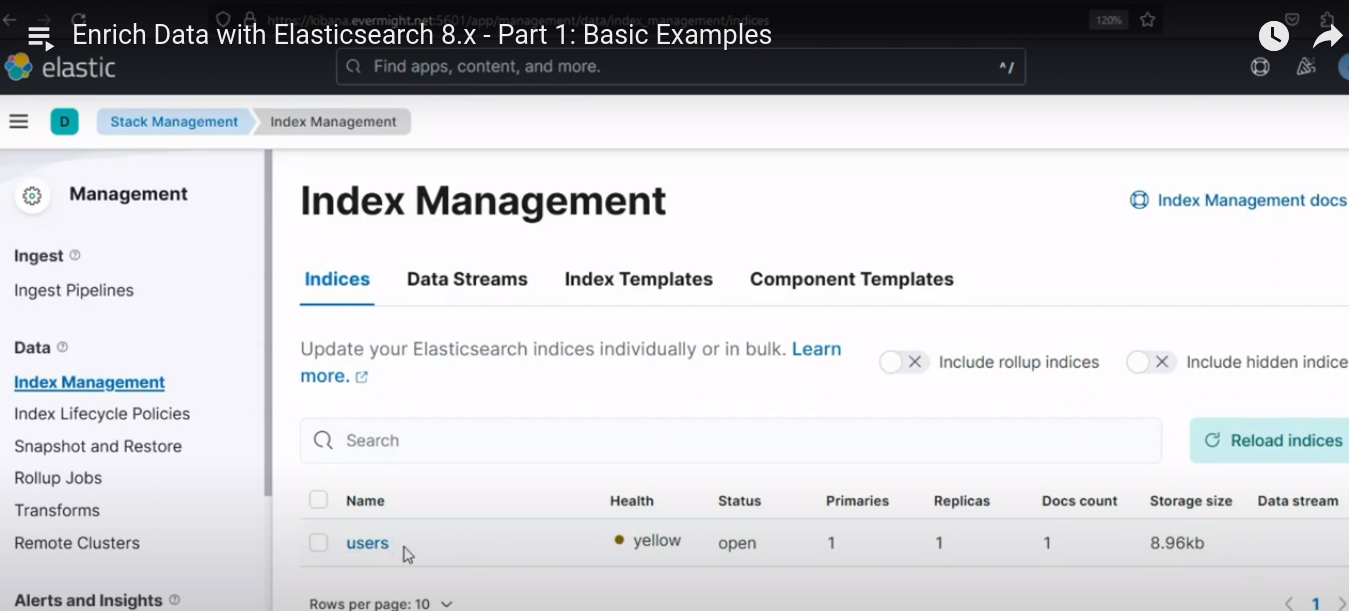 Index créé avec succès
Index créé avec succès
Étape 2 : Configurer une politique d’enrichissement [07:58]
À Kibana, allez à Outils de développement > Console. Collez la commande ci-dessous dans la console, et lorsque vous exécutez cette commande de politique : la politique donnera des instructions sur la façon de remplir les données entrantes avec les données de l'index source.
PUT /_enrich/policy/users-policy
{
"match": {
"indices": "users",
"match_field": "email",
"enrich_fields": ["first_name", "last_name", "city", "zip", "state"]
}
}
Utilisez la commande ci-dessous pour créer un index enrichi pour la politique.
POST /_enrich/policy/users-policy/_execute?wait_for_completion=false
Après l'exécution, il devrait produire un résultat similaire à l'image ci-dessous ;
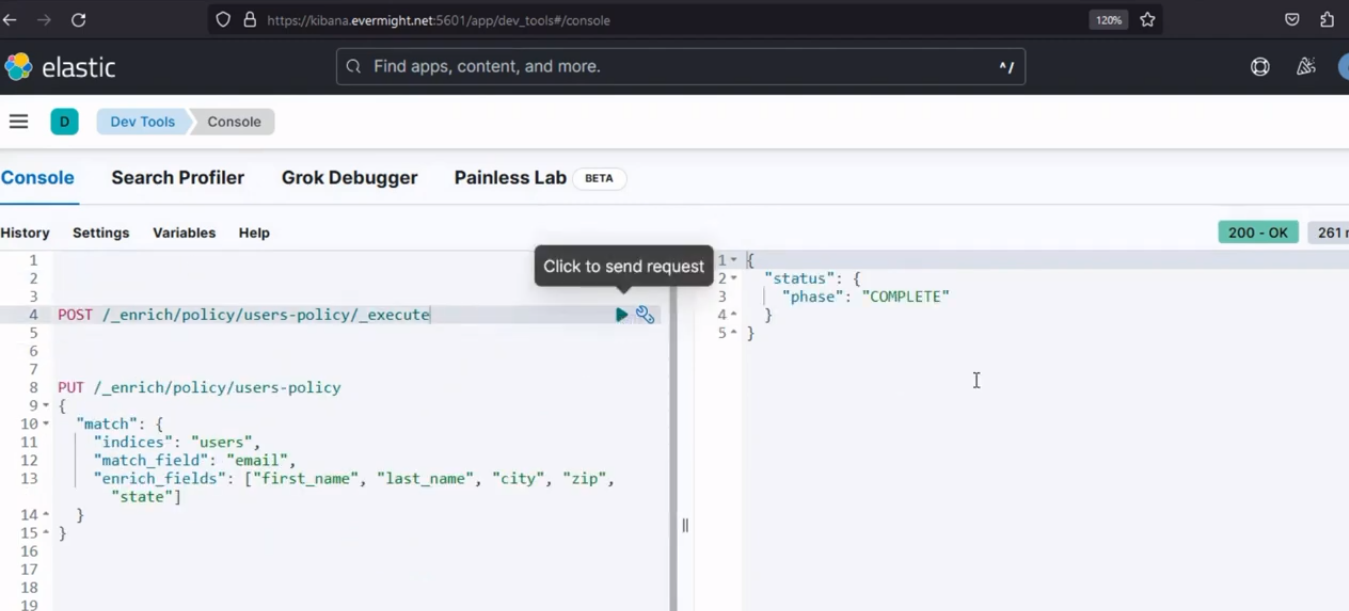 Résultat de la console pour l'étape 2
Résultat de la console pour l'étape 2
Pour confirmer que l'index a été enrichi avec succès, accédez à Gestion de la pile > Gestion des index, basculer le inclure des indices cachés Activez le bouton, puis rechargez les index. Vous devriez obtenir un résultat similaire à l'image ci-dessous :
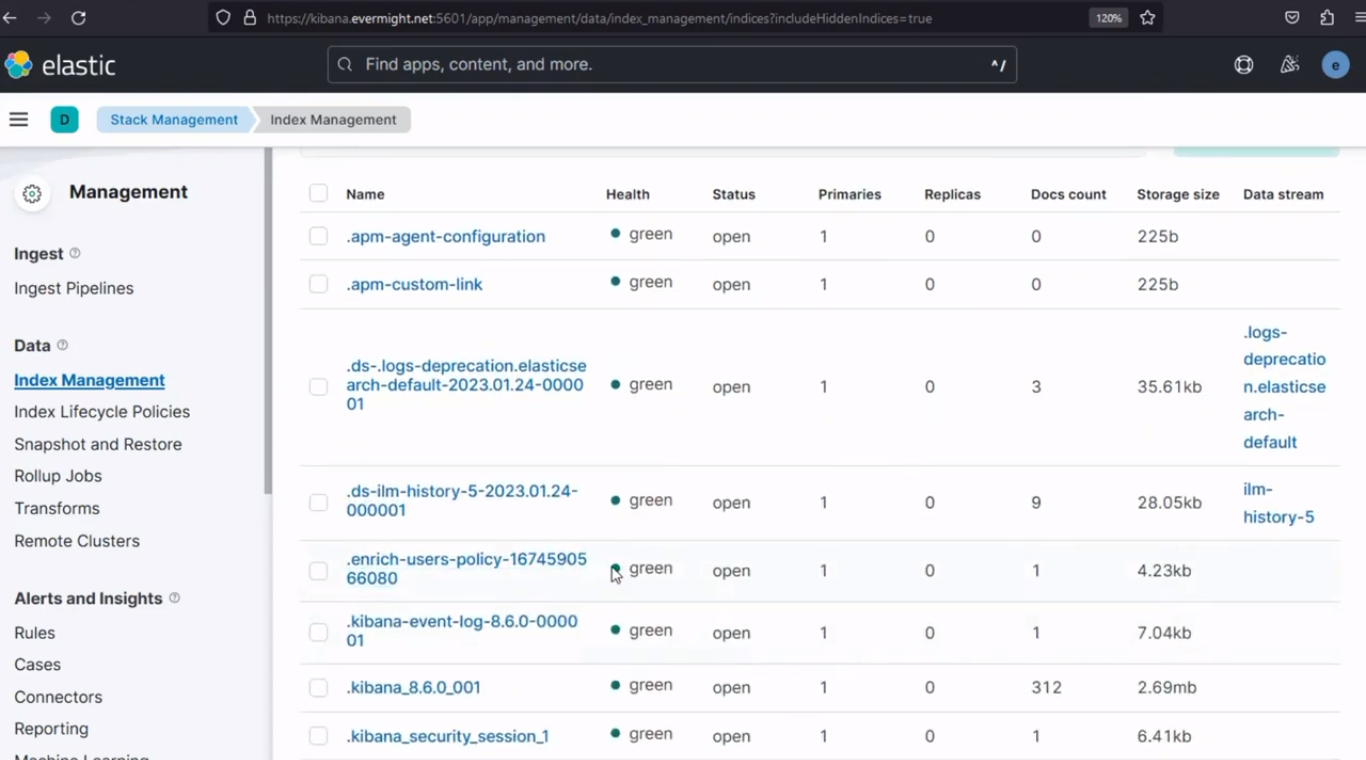 Index enrichi avec succès
Index enrichi avec succès
Étape 3 : Configurer un pipeline d’ingestion [11:05]
Créez un pipeline d'ingestion avec un processeur d'enrichissement. Utilisez la commande ci-dessous :
PUT /_ingest/pipeline/user_lookup
{
"processors" : [
{
"enrich" : {
"description": "Add 'user' data based on 'email'",
"policy_name": "users-policy",
"field" : "email",
"target_field": "user",
"max_matches": "1"
}
}
]
}
Après l'exécution, il devrait produire un résultat similaire à l'image ci-dessous ;
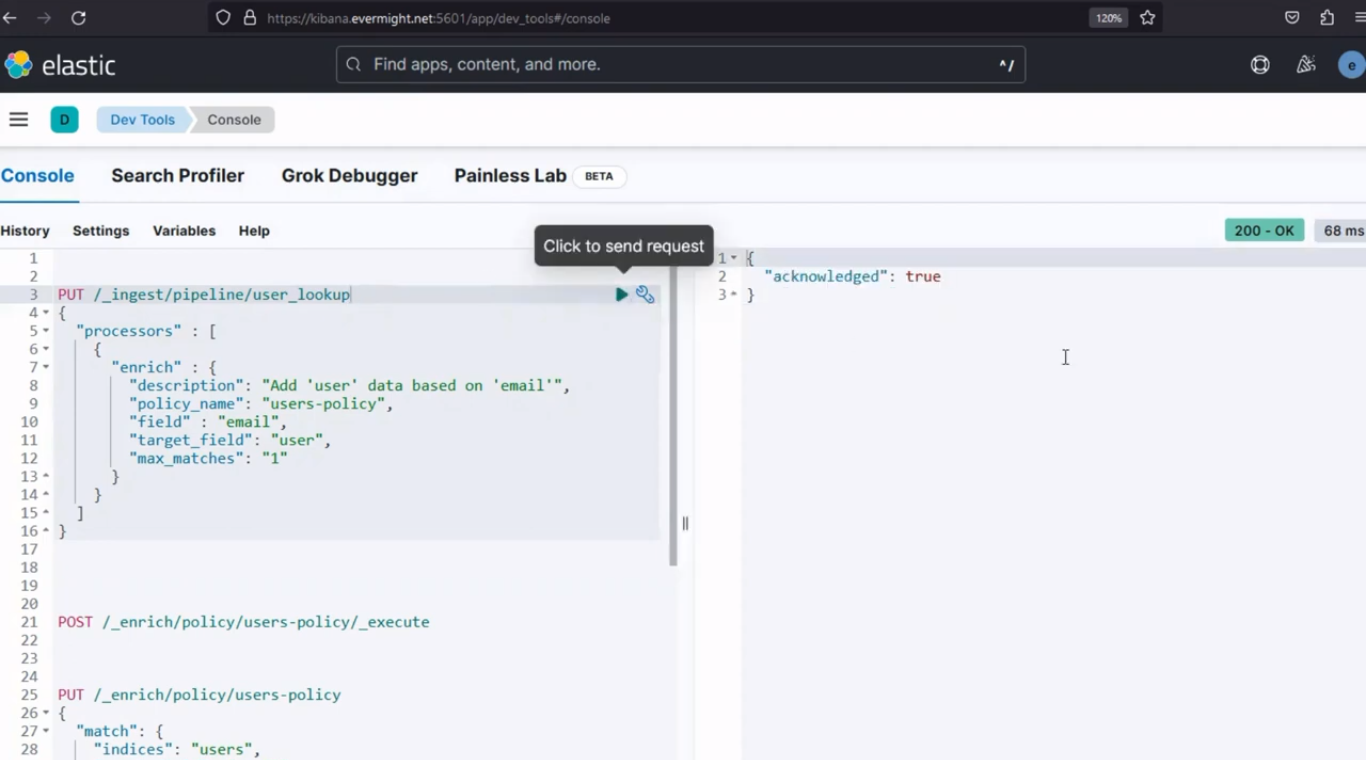 Résultat de la console pour l'étape 3
Résultat de la console pour l'étape 3
Pour confirmer que l'indexation du pipeline d'ingestion a été effectuée avec succès, accédez à Gestion de la pile > Pipelines d'ingestion. Et vous devriez voir un résultat similaire à l'image ci-dessous :
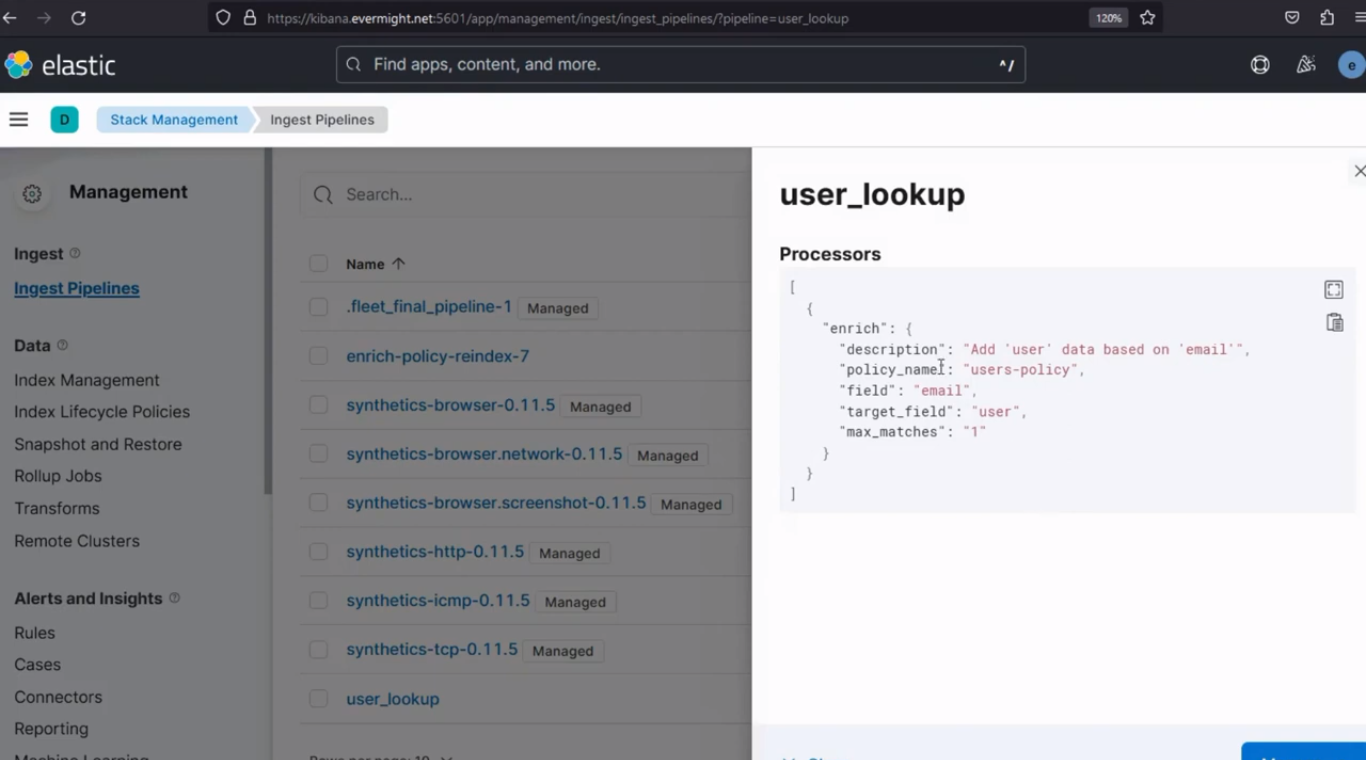 L'index du pipeline d'ingestion a été créé avec succès
L'index du pipeline d'ingestion a été créé avec succès
Étape 4 : Insérer un document à l'aide du pipeline d'ingestion [13:16]
Utilisez le pipeline d'ingestion ci-dessous pour insérer un nouveau document. Le document entrant doit inclure le champ spécifié dans votre processeur d'enrichissement.
PUT /my-index-000001/_doc/my_id?pipeline=user_lookup
{
"email": "mardy.brown@asciidocsmith.com"
}
Après l'exécution, il devrait produire un résultat similaire à l'image ci-dessous ;
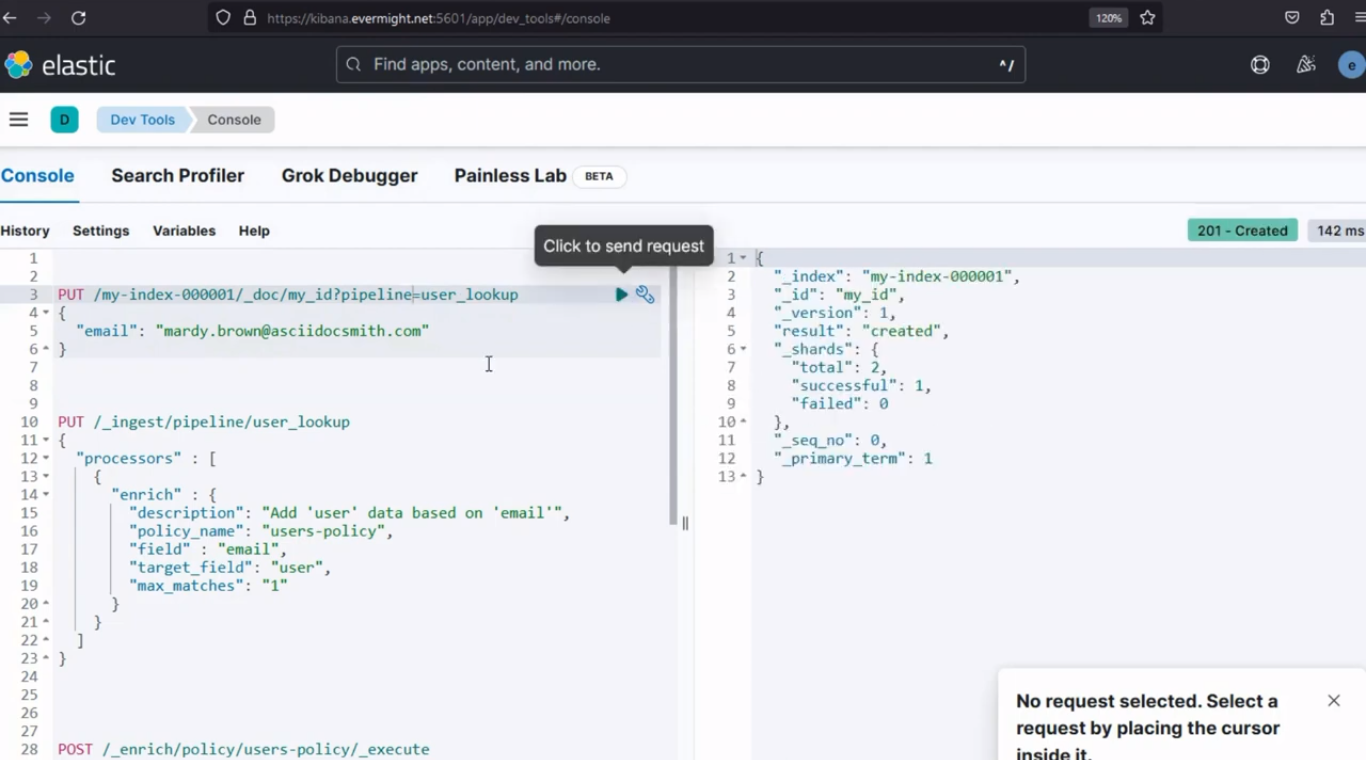 Résultat de la console pour l'étape 4
Résultat de la console pour l'étape 4
Et lorsque vous effectuez une requête GET, vous verrez le résultat :
GET /my-index-000001/_doc/my_id
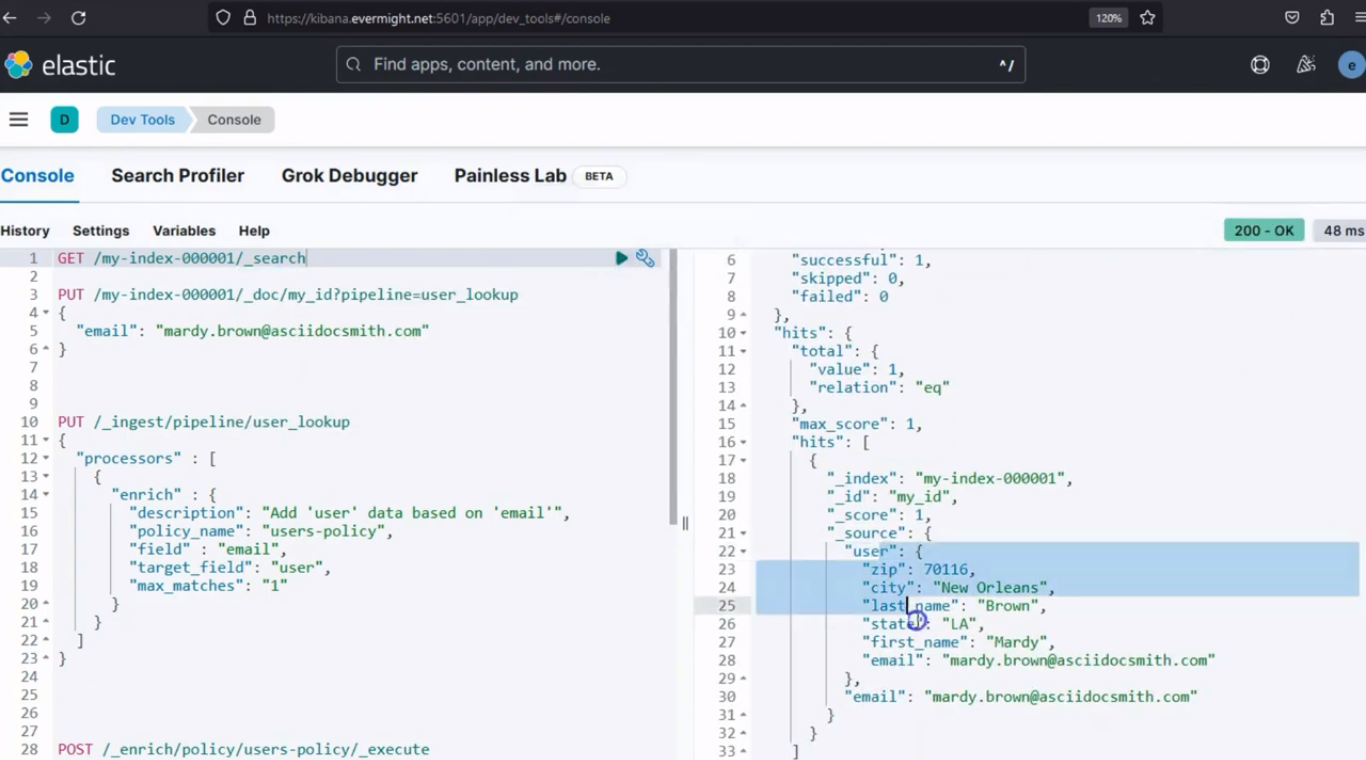 Résultat de la console pour les documents
Résultat de la console pour les documents
Insérons un autre document dans l'index source
POST /users/_doc
{
"email": "test@test.com",
"first_name": "Test",
"last_name": "Brown",
"city": "New Orleans",
"county": "Orleans",
"state": "LA",
"zip": 70116,
"web": "mardy.asciidocsmith.com"
}
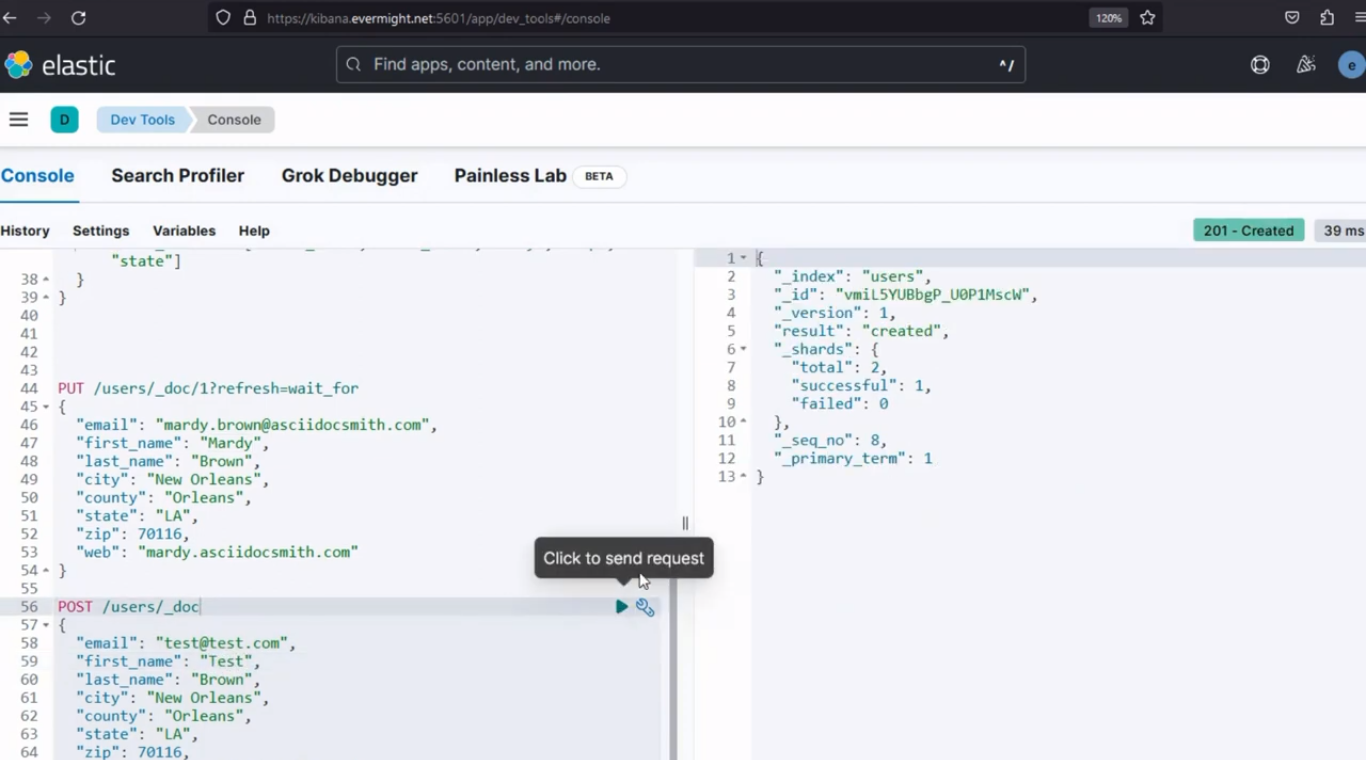 Résultat de la console pour l'insertion d'un nouveau document dans l'index source
Résultat de la console pour l'insertion d'un nouveau document dans l'index source
Exécutez ensuite la commande ci-dessous :
PUT /my-index-000001/_doc/pipeline=user_lookup
{
"email": "test@test.com"
}
Après l'exécution, il devrait produire un résultat similaire à l'image ci-dessous ;
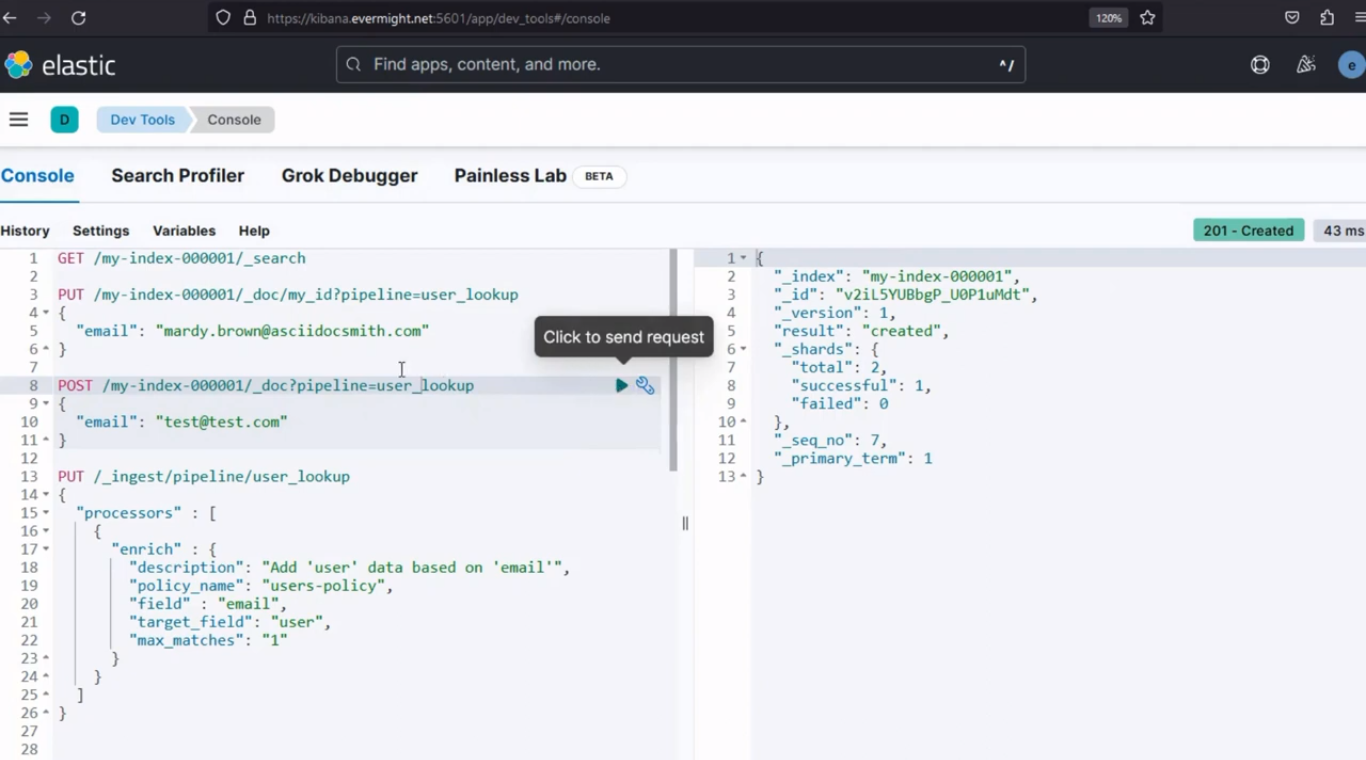 Résultat de la console pour l'utilisation de la commande POST pour insérer un document
Résultat de la console pour l'utilisation de la commande POST pour insérer un document
Comment enrichir les données en fonction de la correspondance de valeurs de plage ? [17:25]
Étape 1 : Configuration d'un index source [17:33]
À Kibana, allez à Outils de développement > Console. Collez la commande ci-dessous dans la console :
PUT /networks
{
"mappings": {
"properties": {
"range": { "type": "ip_range" },
"name": { "type": "keyword" },
"department": { "type": "keyword" }
}
}
}
Vous devriez obtenir un résultat similaire à l’image ci-dessous :
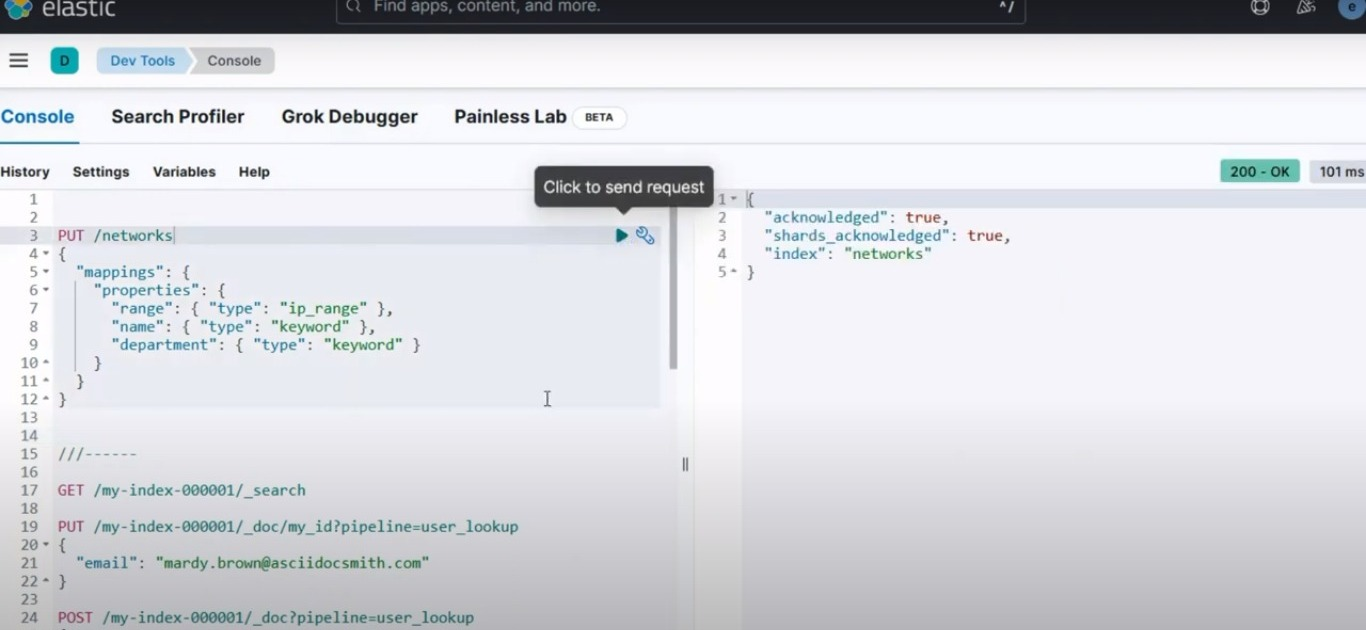 Résultat de la console pour la configuration d'un index
Résultat de la console pour la configuration d'un index
Étape 2 : Insérer le document dans l’index source [20:10]
Exécutez la commande ci-dessous pour insérer un document dans l'index source qui a été créé
PUT /networks/_doc/1?refresh=wait_for
{
"range": "10.100.0.0/16",
"name": "production",
"department": "OPS"
}
Vous devriez obtenir un résultat comme celui-ci :
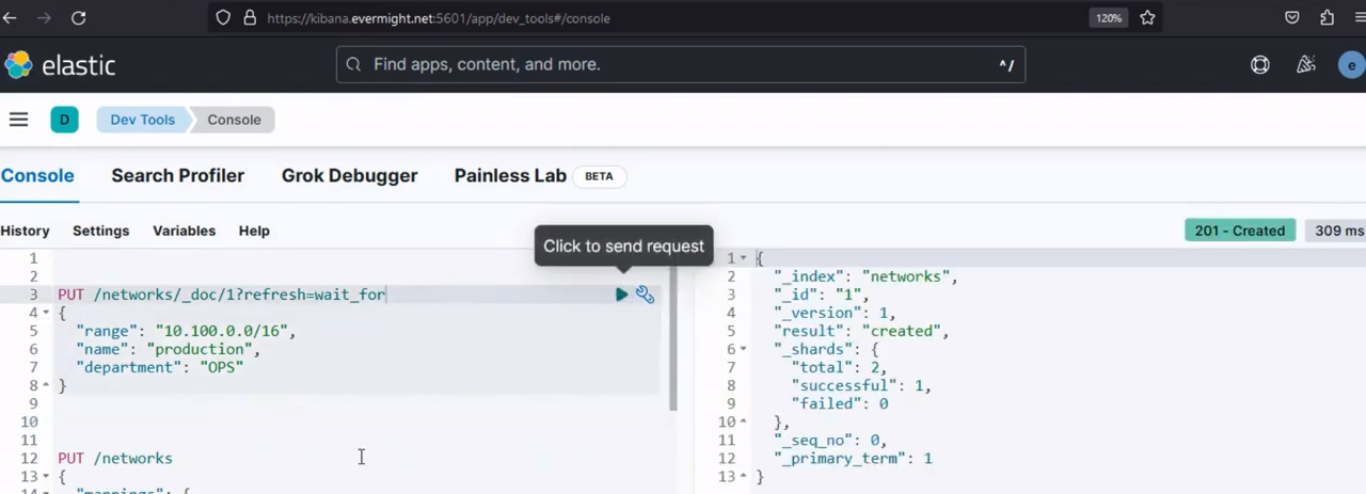 Résultat de la console pour l'insertion de documents dans l'index source
Résultat de la console pour l'insertion de documents dans l'index source
Étape 3 : Configurer une politique d’enrichissement [21:20]
Configurez la politique d’enrichissement avec la commande ci-dessous :
PUT /_enrich/policy/networks-policy
{
"range": {
"indices": "networks",
"match_field": "range",
"enrich_fields": ["name", "department"]
}
}
Utilisez la commande ci-dessous pour créer un index enrichi pour la politique.
POST /_enrich/policy/networks-policy/_execute?wait_for_completion=false
Après l'exécution, il devrait produire un résultat similaire à l'image ci-dessous ;
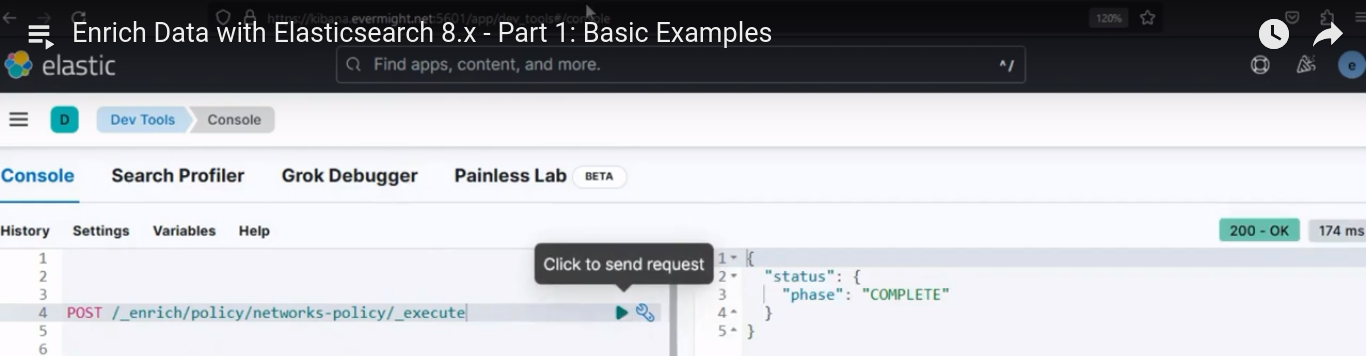 Résultat de la console pour l'étape 3
Résultat de la console pour l'étape 3
Pour confirmer que l'index a été enrichi avec succès, accédez à Gestion de la pile > Gestion des index, basculer le inclure des indices cachés bouton On, puis recharger les index.
Étape 4 : Créer un pipeline d’ingestion [22:58]
Créez un pipeline d’ingestion et ajoutez un processeur d’enrichissement :
PUT /_ingest/pipeline/networks_lookup
{
"processors" : [
{
"enrich" : {
"description": "Add 'network' data based on 'ip'",
"policy_name": "networks-policy",
"field" : "ip",
"target_field": "network",
"max_matches": "10"
}
}
]
}
Utilisez le pipeline d'ingestion ci-dessous pour insérer un nouveau document. Le document entrant doit inclure le champ spécifié dans votre processeur d'enrichissement.
PUT /my-index-000001/_doc/my_id?pipeline=networks_lookup
{
"ip": "10.100.34.1"
}
Après l'exécution, il devrait produire un résultat similaire à l'image ci-dessous ;
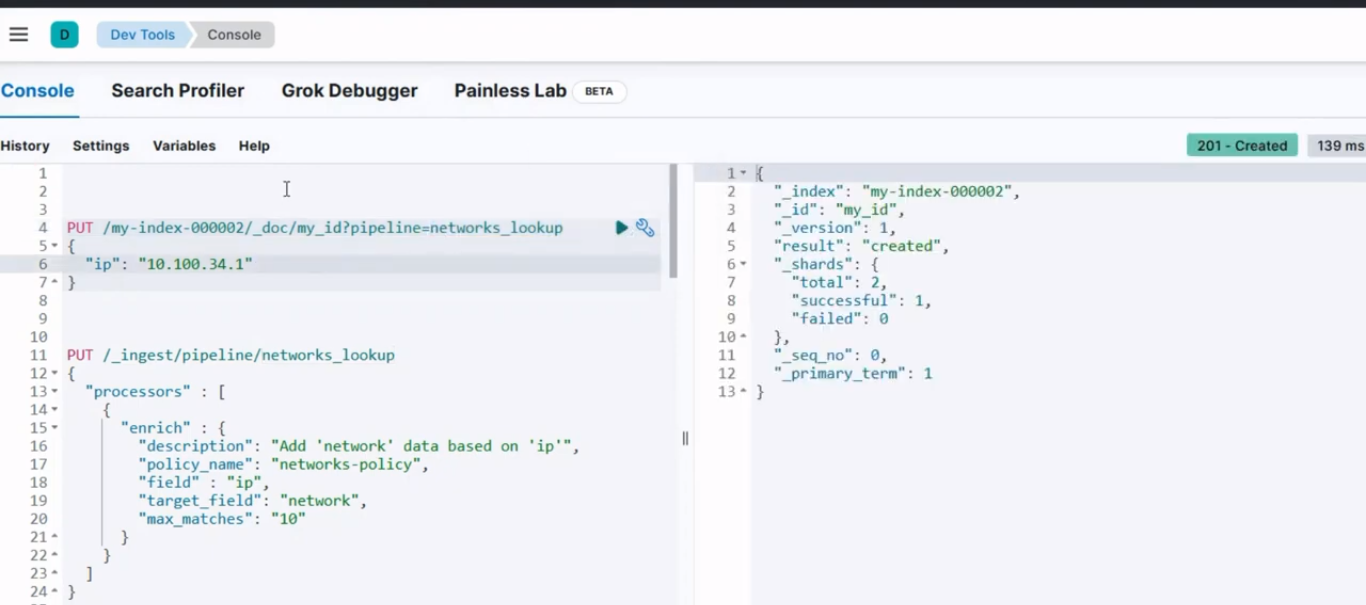 Résultat de la console pour l'étape 4
Résultat de la console pour l'étape 4
Et lorsque vous effectuez une requête GET, vous verrez le résultat :
GET /my-index-000001/_doc/my_id
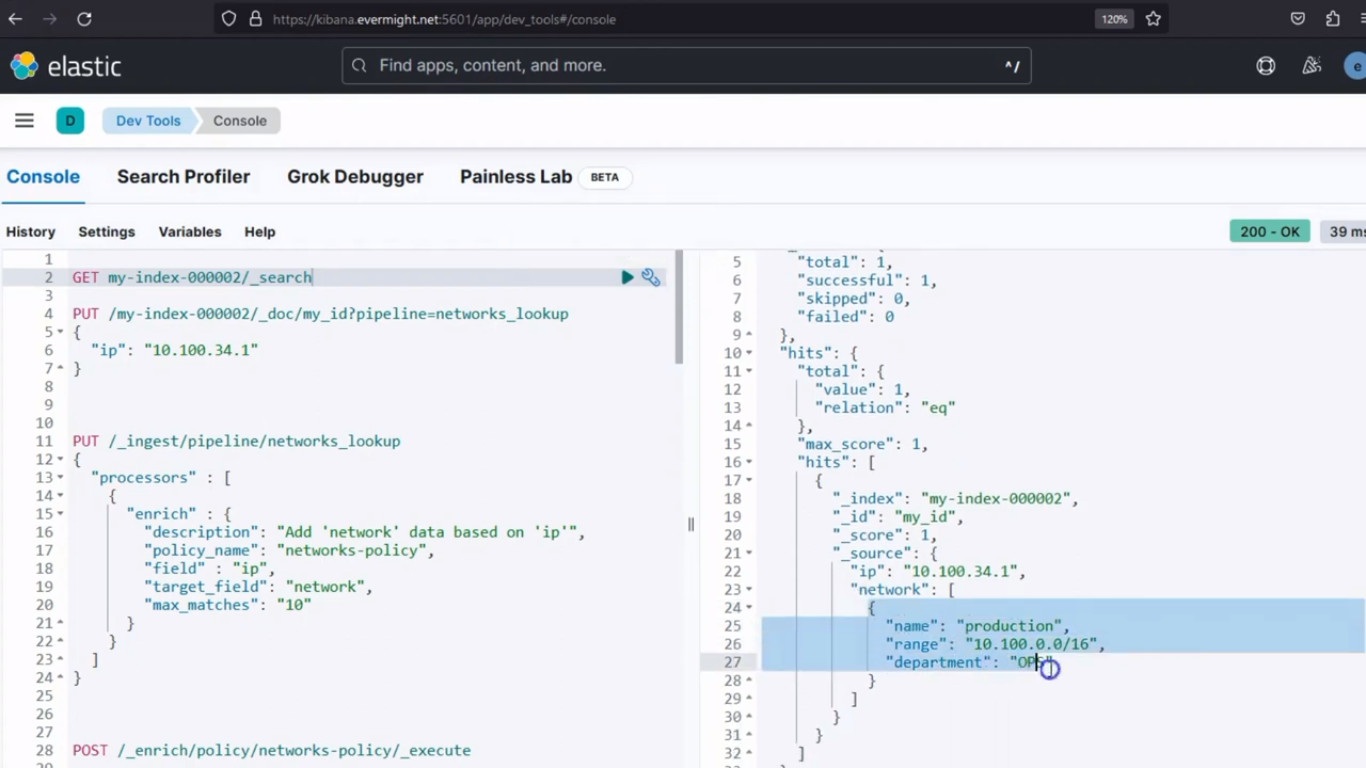 Résultat de la console pour les documents
Résultat de la console pour les documents
Comment enrichir les données grâce à la « correspondance géolocalisée » [25:23]
Étape 1 : Configuration d'un index source [26:10]
À Kibana, allez à Outils de développement > Console. Collez la commande ci-dessous dans la console :
PUT /postal_codes
{
"mappings": {
"properties": {
"location": {
"type": "geo_shape"
},
"postal_code": {
"type": "keyword"
}
}
}
}
Vous devriez obtenir un résultat similaire à l’image ci-dessous :
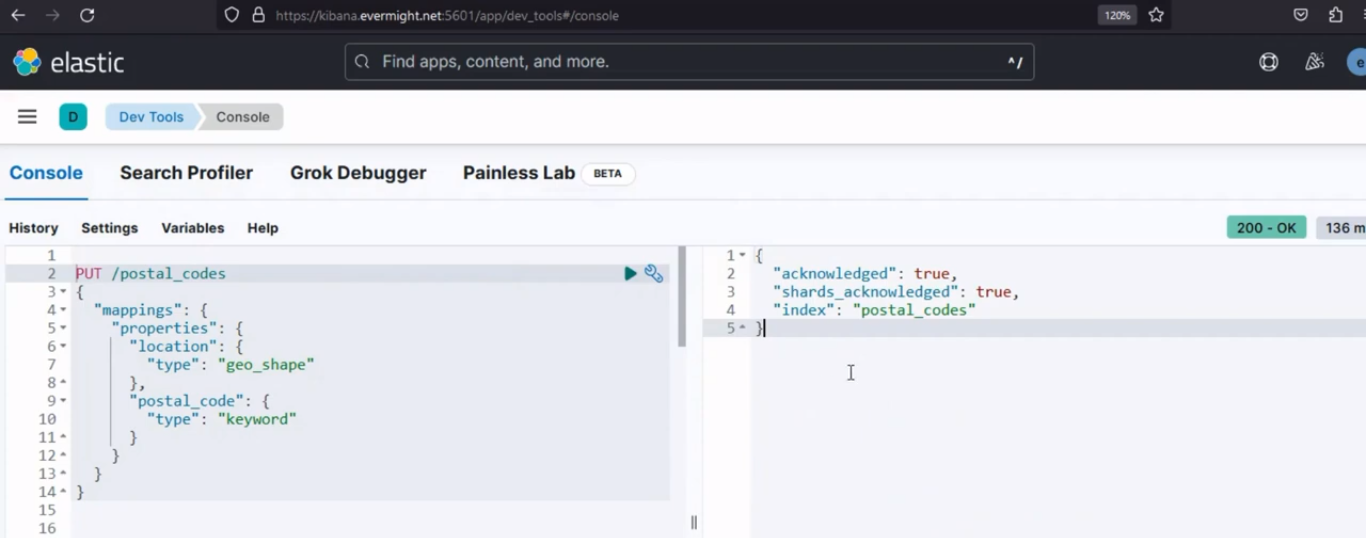 Résultat de la console pour la configuration d'un index
Résultat de la console pour la configuration d'un index
Étape 2 : Insérer le document dans l’index source [27:00]
Indexez les données enrichies dans l'index source, en utilisant la commande ci-dessous :
PUT /postal_codes/_doc/1?refresh=wait_for
{
"location": {
"type": "envelope",
"coordinates": [[13.0, 53.0], [14.0, 52.0]]
},
"postal_code": "96598"
}
Vous devriez obtenir un résultat comme celui-ci :
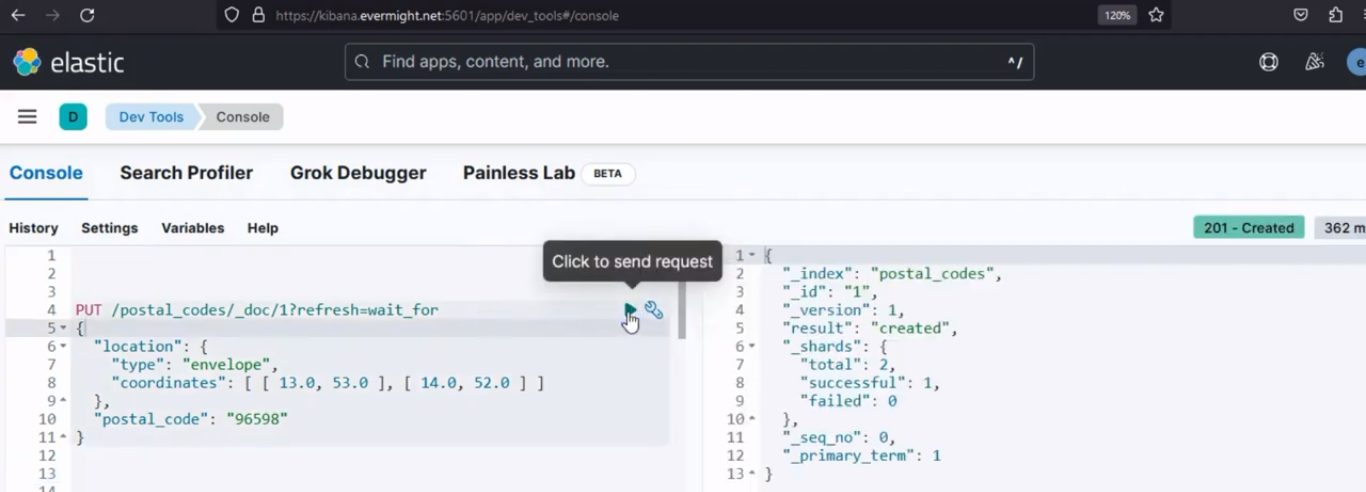 Résultat de la console pour l'insertion de documents dans l'index source
Résultat de la console pour l'insertion de documents dans l'index source
Étape 3 : Configurer une politique d’enrichissement [27:38]
Configurez la politique d’enrichissement avec la commande ci-dessous :
PUT /_enrich/policy/postal_policy
{
"geo_match": {
"indices": "postal_codes",
"match_field": "location",
"enrich_fields": [ "location", "postal_code" ]
}
}
Utilisez la commande ci-dessous pour créer un index enrichi pour la politique.
POST /_enrich/policy/postal_policy/_execute?wait_for_completion=false
Après l'exécution, il devrait produire un résultat similaire à l'image ci-dessous ;
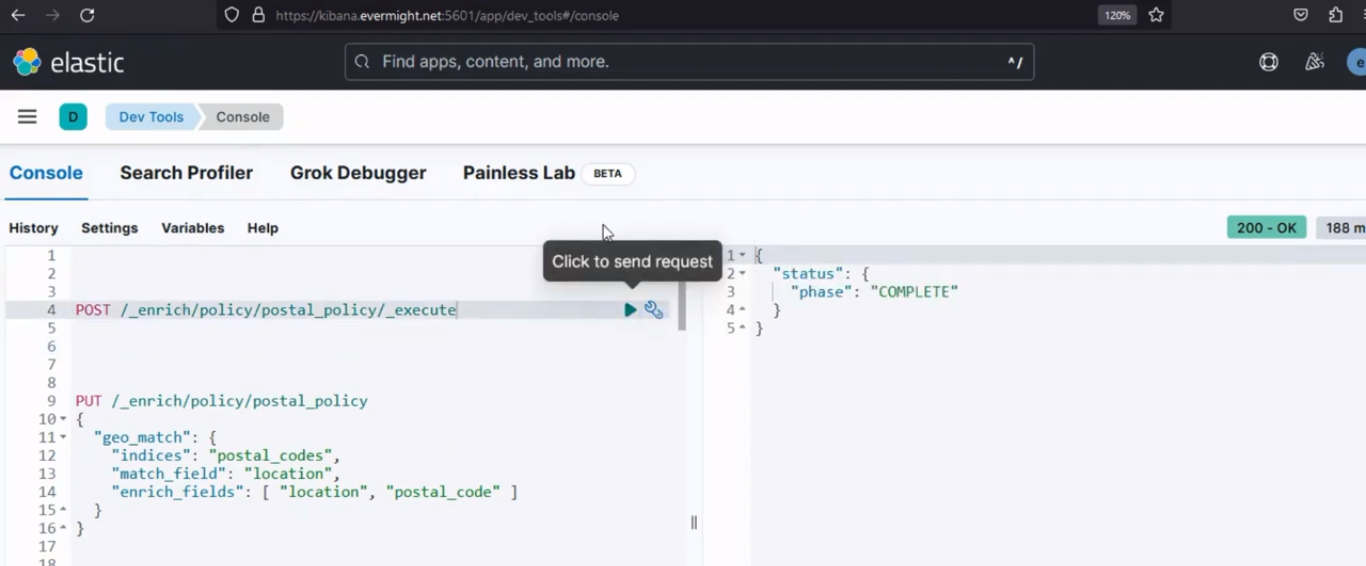 Résultat de la console pour l'étape 3
Résultat de la console pour l'étape 3
Pour confirmer que l'index a été enrichi avec succès, accédez à Gestion de la pile > Gestion des index, basculer le inclure des indices cachés bouton On, puis recharger les index.
Étape 4 : Créer un pipeline d’ingestion [28:51]
Créez un pipeline d’ingestion et ajoutez un processeur d’enrichissement :
PUT /_ingest/pipeline/postal_lookup
{
"processors": [
{
"enrich": {
"description": "Add 'geo_data' based on 'geo_location'",
"policy_name": "postal_policy",
"field": "geo_location",
"target_field": "geo_data",
"shape_relation": "INTERSECTS"
}
}
]
}
Utilisez le pipeline d'ingestion ci-dessous pour insérer un nouveau document. Le document entrant doit inclure le champ spécifié dans votre processeur d'enrichissement.
PUT /users2/_doc/0?pipeline=postal_lookup
{
"first_name": "Mardy",
"last_name": "Brown",
"geo_location": "POINT (13.5 52.5)"
}
Après l'exécution, il devrait produire un résultat similaire à l'image ci-dessous ;
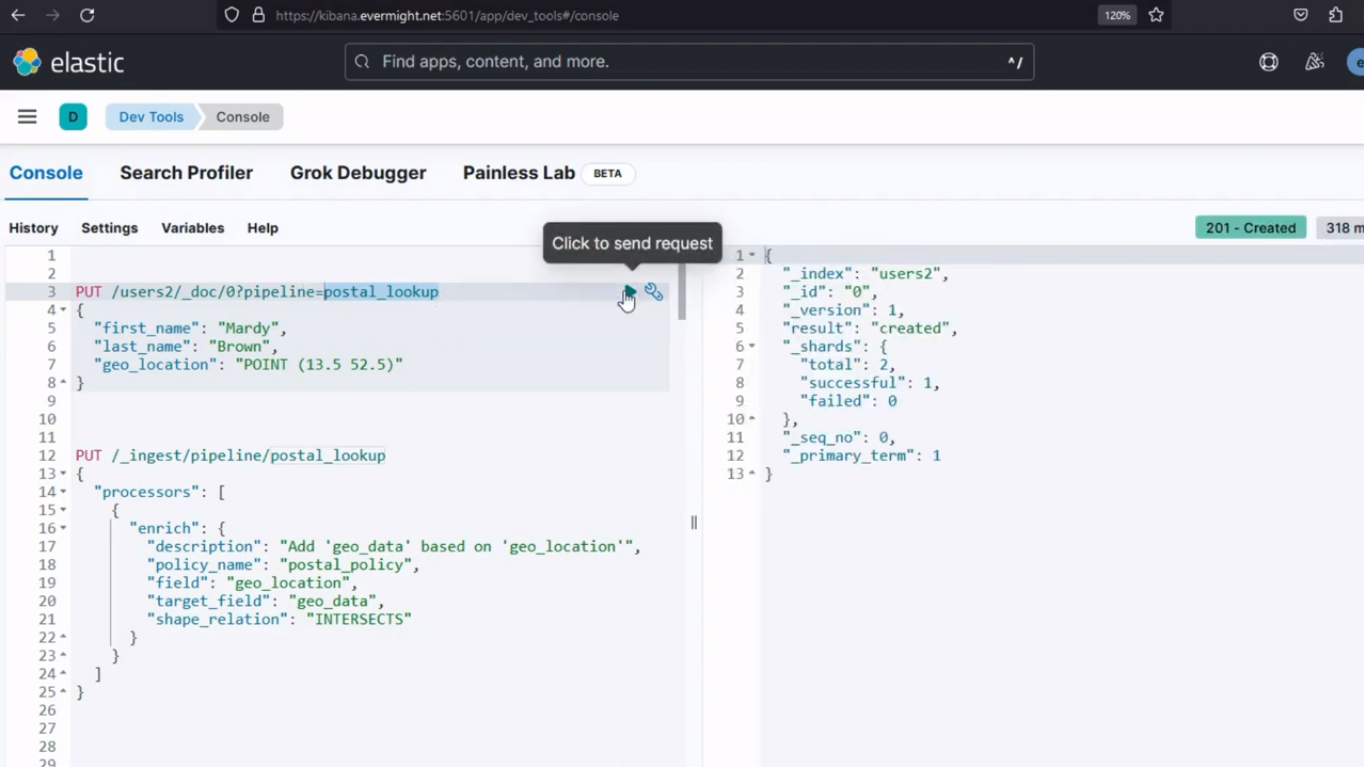 Résultat de la console pour l'étape 4
Résultat de la console pour l'étape 4
Et lorsque vous effectuez une requête GET, vous verrez le résultat :
GET /users2/_search
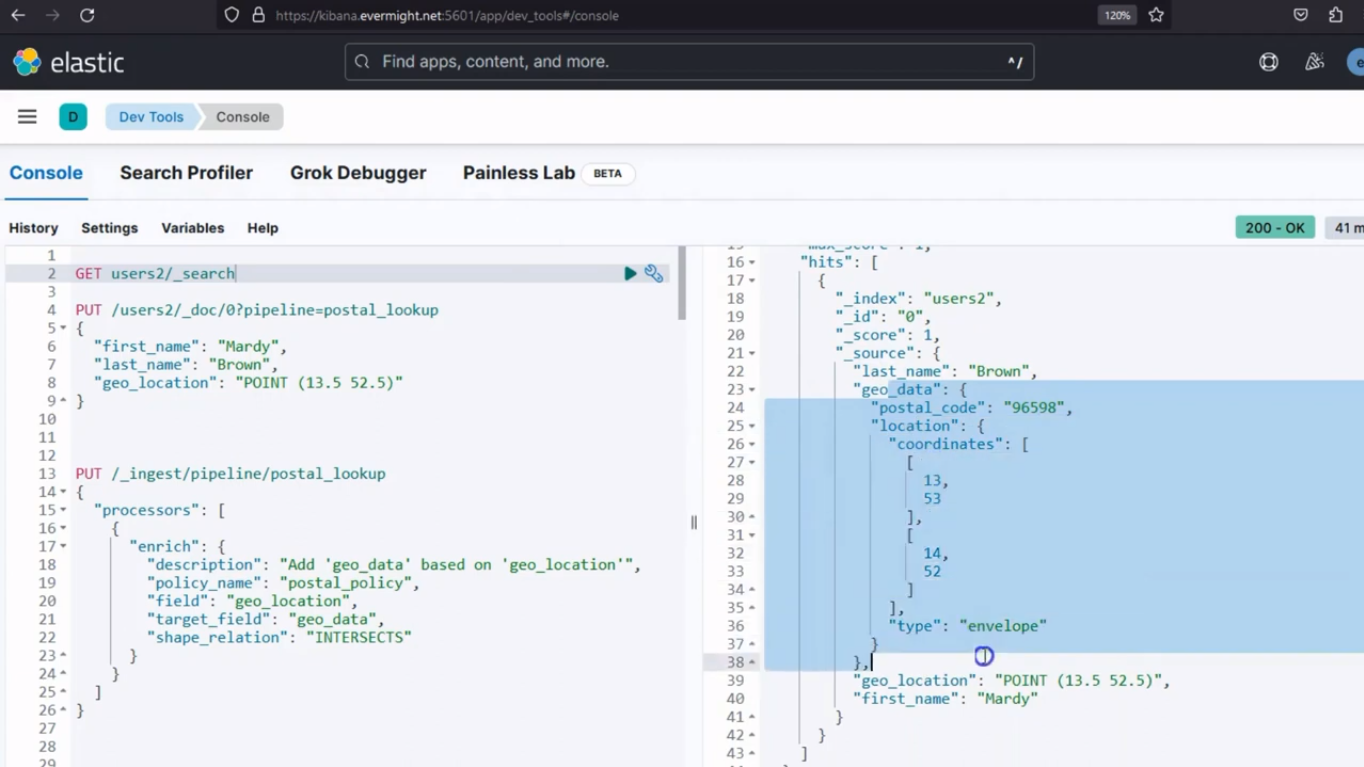 Résultat de la console pour les documents
Résultat de la console pour les documents