
Einführung
Code auf Github: Elasticsearch-Datenanreicherung
Wenn Sie Elasticsearch und Kibana noch nicht eingerichtet haben, dann Befolgen Sie diese Anweisungen.
Dieses Video setzt voraus, dass Sie Öffentlich signierte Zertifikate. Wenn Sie Selbstsignierte Zertifikate, hier klicken Wird noch bekannt gegeben.
Anforderungen
- Eine laufende Instanz von Elasticsearch und Kibana.
- Eine Instanz eines anderen Ubuntu 20.04-Servers, auf dem ein beliebiger Dienst ausgeführt wird.
Verfahren
Definition der Datenanreicherung [00:09]
Gehen Sie zum spezifischen Zeitstempel des Videos, um mehr darüber zu erfahren, was Datenanreicherung bedeutet.
So reichern Sie Daten basierend auf „Exact Value Match“ an [05:47]
Schritt 1: Einrichten eines Quellindex [06:22]
Gehen Sie in Kibana zu Entwicklertools > Konsole. Fügen Sie den folgenden Befehl in die Konsole ein. Wenn Sie diesen Befehl ausführen, erstellt Elasticsearch automatisch einen neuen Index, fügt diese Daten hinzu und führt dann für jedes Feld eine automatische Zuordnung durch.
PUT /users/_doc/1?refresh=wait_for
{
"email": "mardy.brown@asciidocsmith.com",
"first_name": "Mardy",
"last_name": "Brown",
"city": "New Orleans",
"county": "Orleans",
"state": "LA",
"zip": 70116,
"web": "mardy.asciidocsmith.com"
}
Nach dem Ausführen sollte ein ähnliches Ergebnis wie im Bild unten erscheinen.
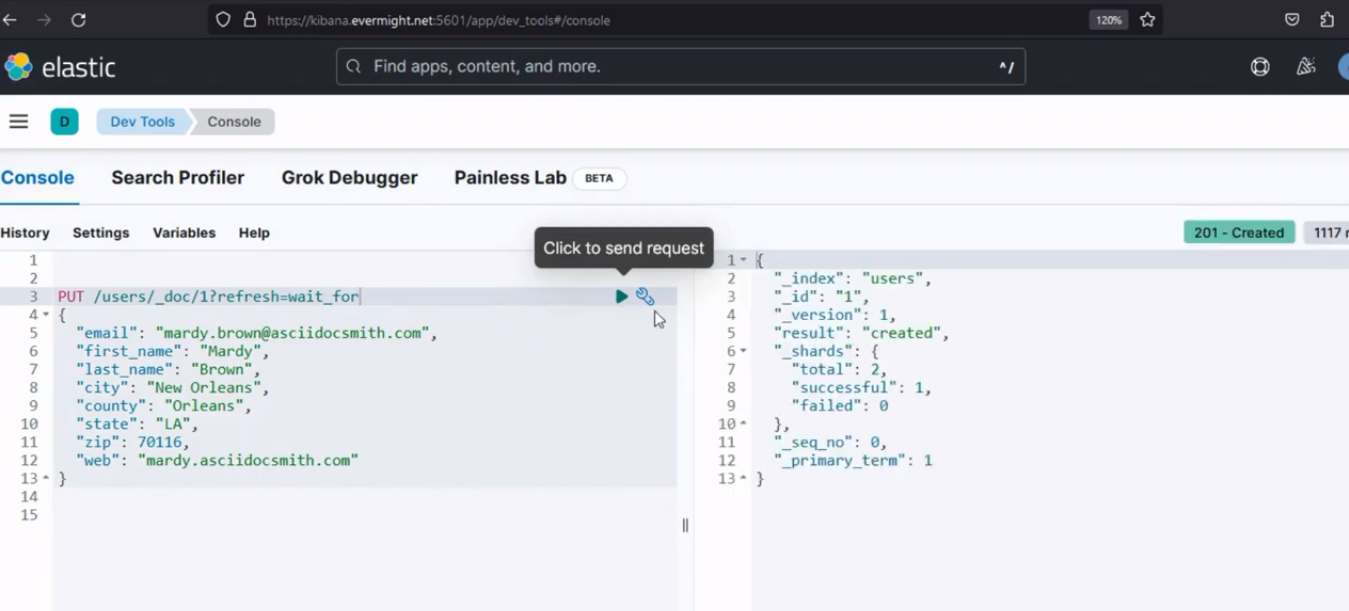 Konsolenergebnis für Schritt 1
Konsolenergebnis für Schritt 1
Um zu bestätigen, dass der Index erfolgreich erstellt wurde, gehen Sie zu Stapelverwaltung > Indexverwaltung. Und Sie sollten ein ähnliches Ergebnis wie im Bild unten sehen:
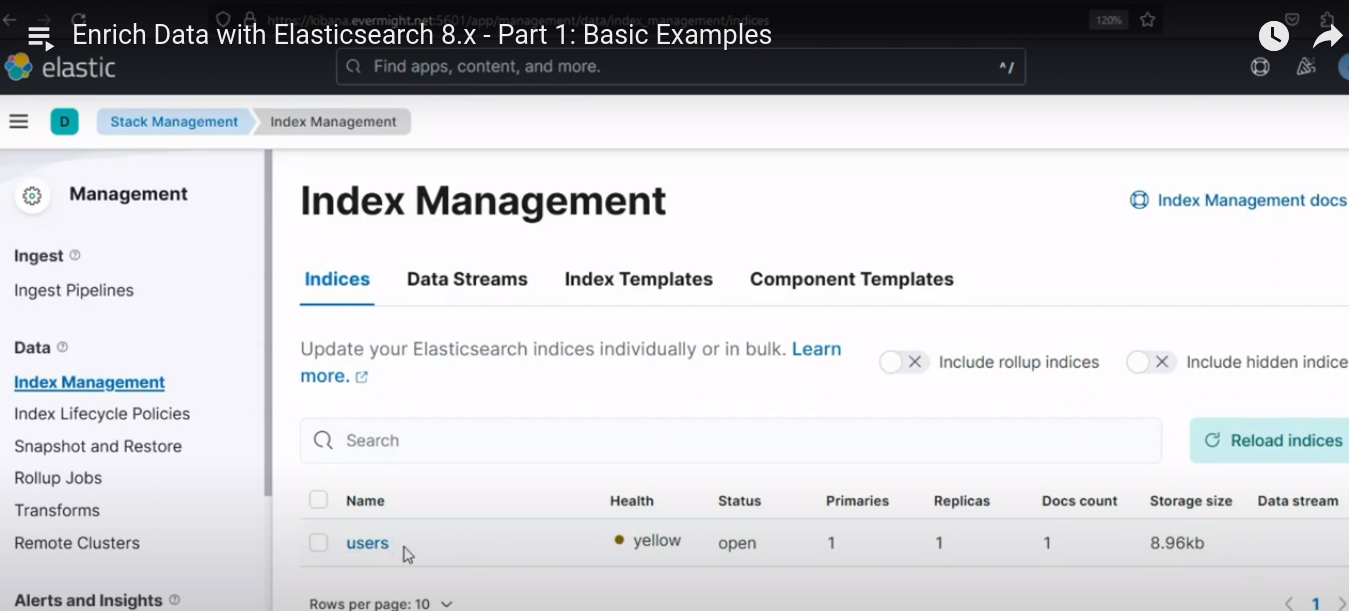 Index erfolgreich erstellt
Index erfolgreich erstellt
Schritt 2: Einrichten einer Anreicherungsrichtlinie [07:58]
Gehen Sie in Kibana zu Entwicklertools > Konsole. Fügen Sie den folgenden Befehl in die Konsole ein. Wenn Sie diesen Richtlinienbefehl ausführen, gibt die Richtlinie Anweisungen zum Auffüllen eingehender Daten mit Daten aus dem Quellindex.
PUT /_enrich/policy/users-policy
{
"match": {
"indices": "users",
"match_field": "email",
"enrich_fields": ["first_name", "last_name", "city", "zip", "state"]
}
}
Verwenden Sie den folgenden Befehl, um einen erweiterten Index für die Richtlinie zu erstellen.
POST /_enrich/policy/users-policy/_execute?wait_for_completion=false
Nach dem Ausführen sollte ein ähnliches Ergebnis wie im Bild unten erscheinen.
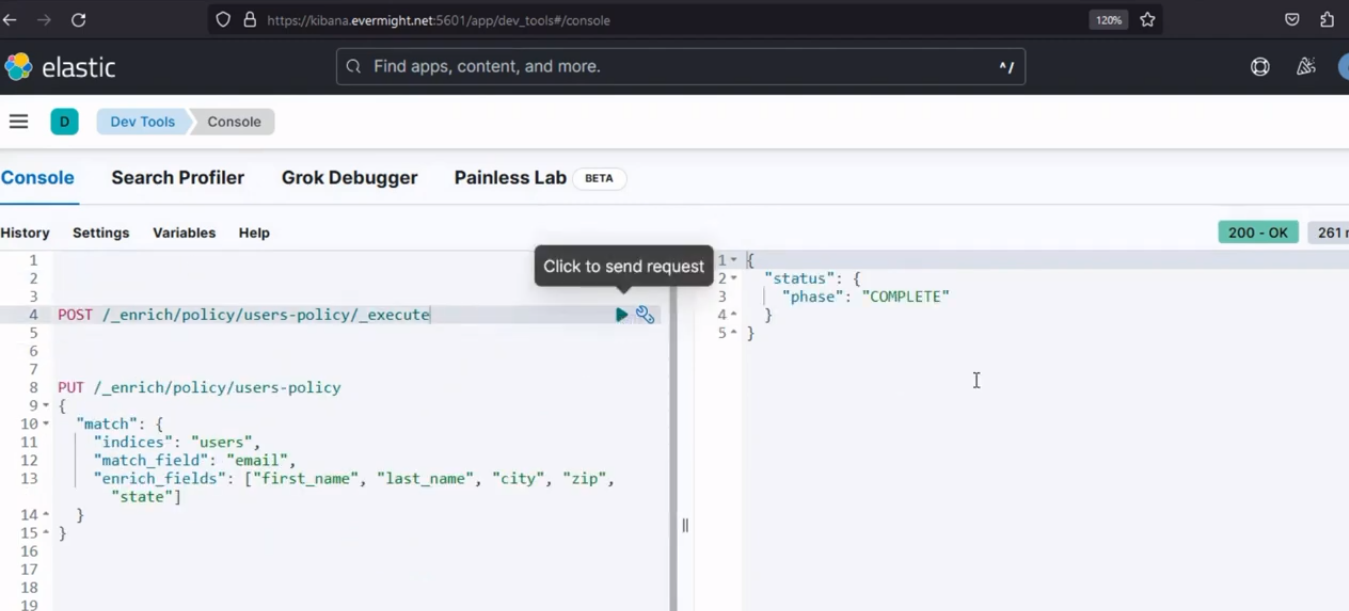 Konsolenergebnis für Schritt 2
Konsolenergebnis für Schritt 2
Um zu bestätigen, dass der Index erfolgreich angereichert wurde, gehen Sie zu Stapelverwaltung > Indexverwaltung, schalten Sie die Versteckte Indizes einschließen Klicken Sie auf „Ein“ und laden Sie die Indizes neu. Das Ergebnis sollte dem unten stehenden Bild ähneln:
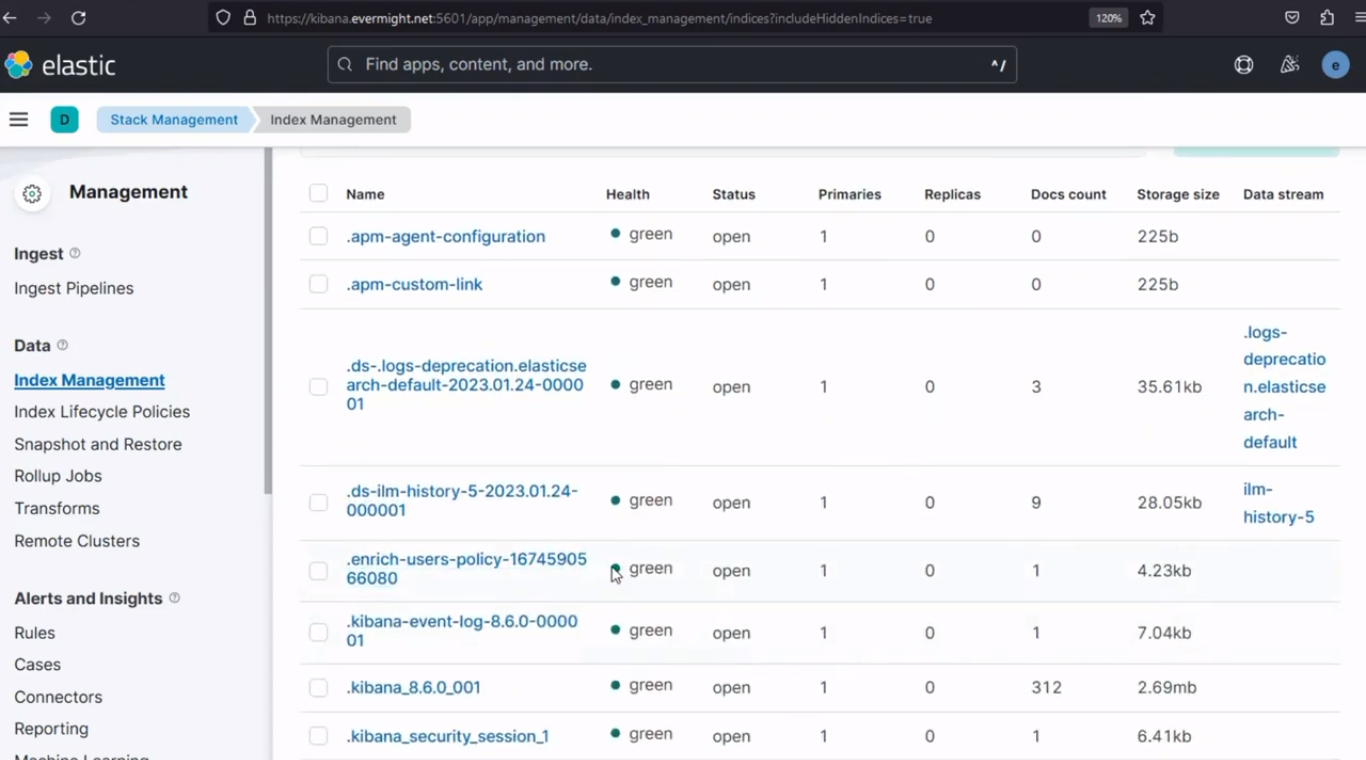 Index erfolgreich angereichert
Index erfolgreich angereichert
Schritt 3: Einrichten einer Ingestion-Pipeline [11:05]
Erstellen Sie eine Ingest-Pipeline mit einem Enrichment-Prozessor. Verwenden Sie dazu den folgenden Befehl:
PUT /_ingest/pipeline/user_lookup
{
"processors" : [
{
"enrich" : {
"description": "Add 'user' data based on 'email'",
"policy_name": "users-policy",
"field" : "email",
"target_field": "user",
"max_matches": "1"
}
}
]
}
Nach dem Ausführen sollte ein ähnliches Ergebnis wie im Bild unten erscheinen.
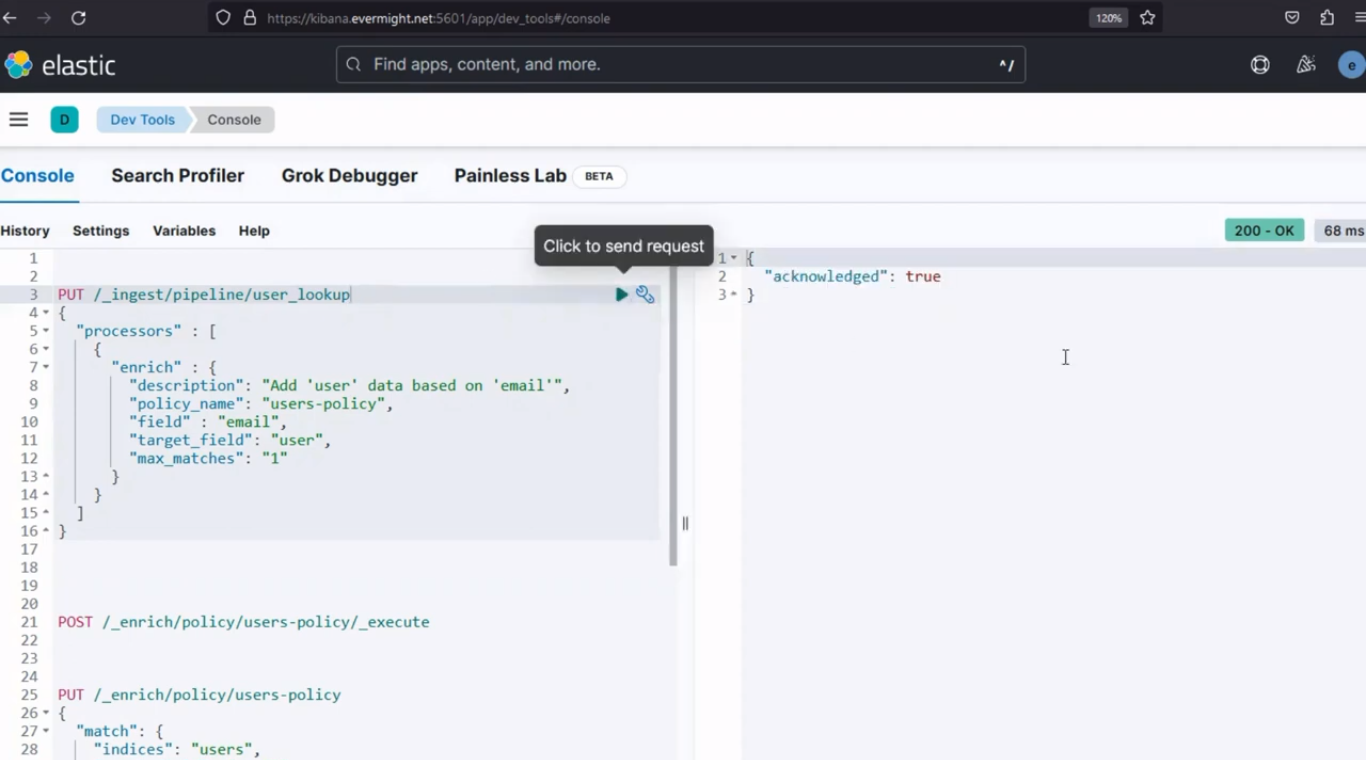 Konsolenergebnis für Schritt 3
Konsolenergebnis für Schritt 3
Um zu bestätigen, dass der Index für die Aufnahmepipeline erfolgreich erstellt wurde, gehen Sie zu Stapelverwaltung > Aufnahme-Pipelines. Und Sie sollten ein ähnliches Ergebnis wie im Bild unten sehen:
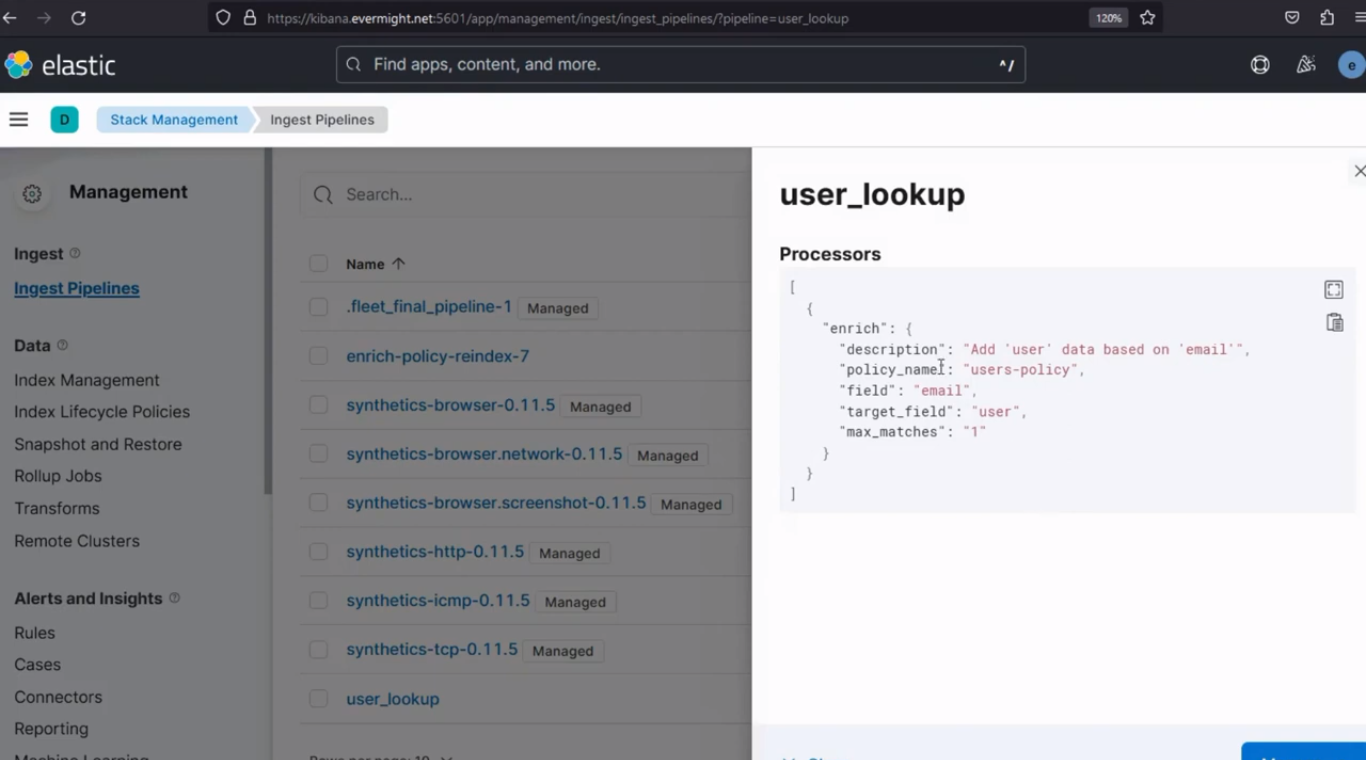 Ingest-Pipeline-Index erfolgreich erstellt
Ingest-Pipeline-Index erfolgreich erstellt
Schritt 4: Dokument mithilfe der Ingestion-Pipeline einfügen [13:16]
Verwenden Sie die unten stehende Ingest-Pipeline, um ein neues Dokument einzufügen. Das eingehende Dokument sollte das in Ihrem Anreicherungsprozessor angegebene Feld enthalten.
PUT /my-index-000001/_doc/my_id?pipeline=user_lookup
{
"email": "mardy.brown@asciidocsmith.com"
}
Nach dem Ausführen sollte ein ähnliches Ergebnis wie im Bild unten erscheinen.
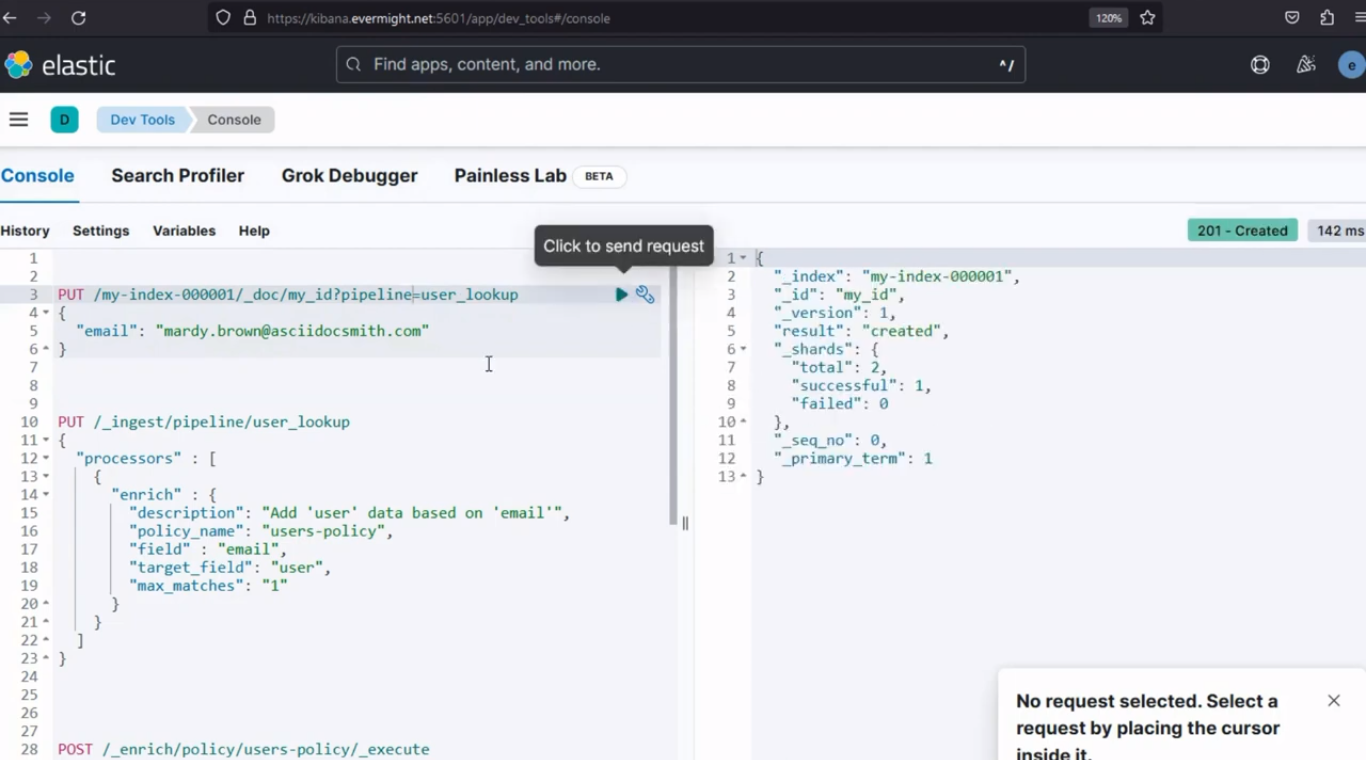 Konsolenergebnis für Schritt 4
Konsolenergebnis für Schritt 4
Und wenn Sie eine GET-Anfrage durchführen, sehen Sie das Ergebnis:
GET /my-index-000001/_doc/my_id
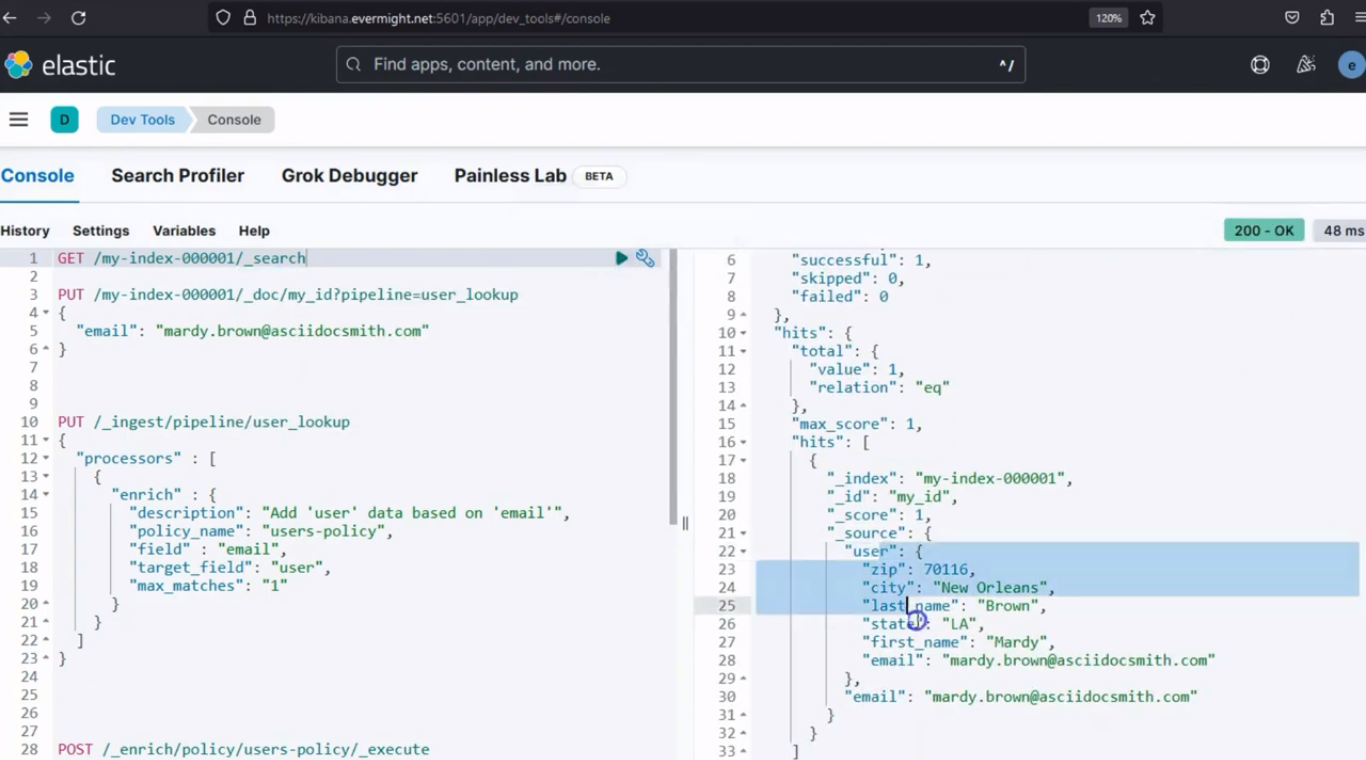 Konsolenergebnis für Dokumente
Konsolenergebnis für Dokumente
Fügen wir ein weiteres Dokument in den Quellindex ein
POST /users/_doc
{
"email": "test@test.com",
"first_name": "Test",
"last_name": "Brown",
"city": "New Orleans",
"county": "Orleans",
"state": "LA",
"zip": 70116,
"web": "mardy.asciidocsmith.com"
}
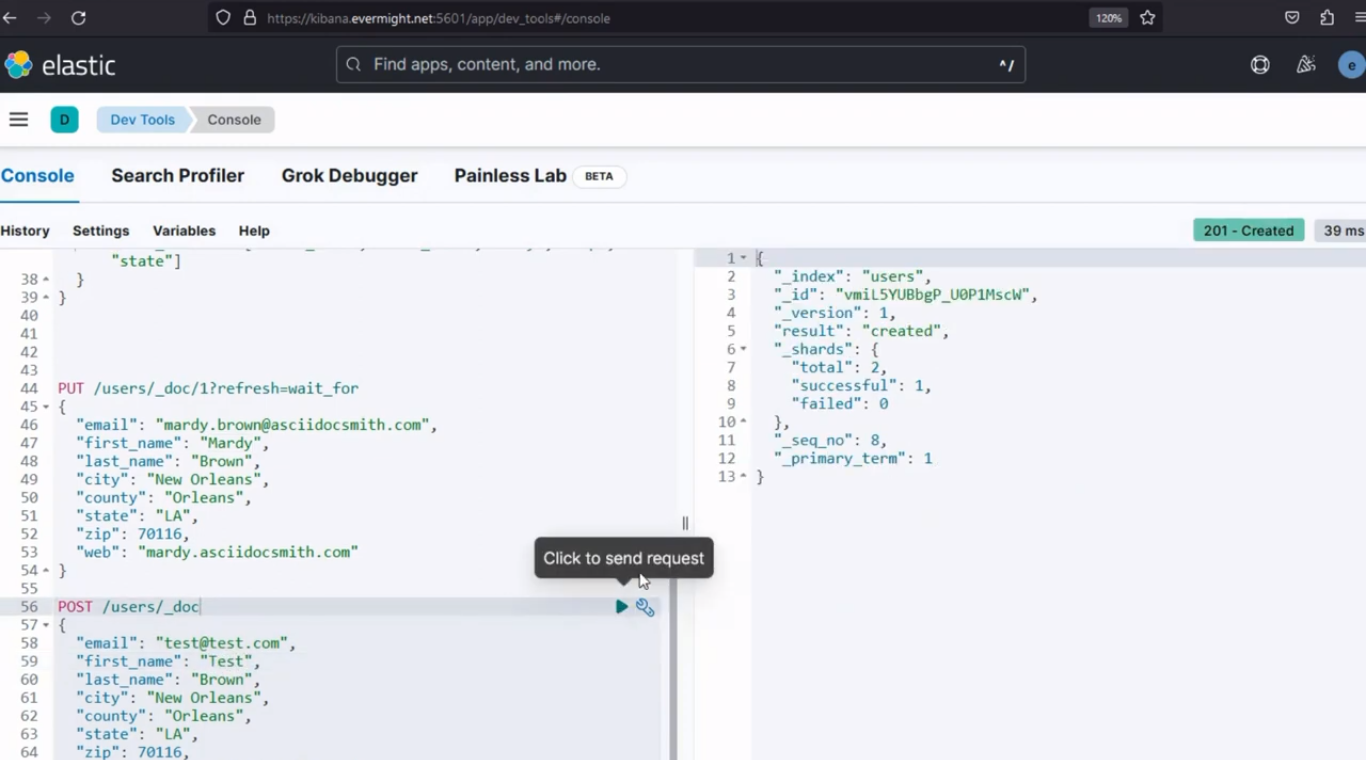 Konsolenergebnis zum Einfügen eines neuen Dokuments in den Quellindex
Konsolenergebnis zum Einfügen eines neuen Dokuments in den Quellindex
Führen Sie dann den folgenden Befehl aus:
PUT /my-index-000001/_doc/pipeline=user_lookup
{
"email": "test@test.com"
}
Nach dem Ausführen sollte ein ähnliches Ergebnis wie im Bild unten erscheinen.
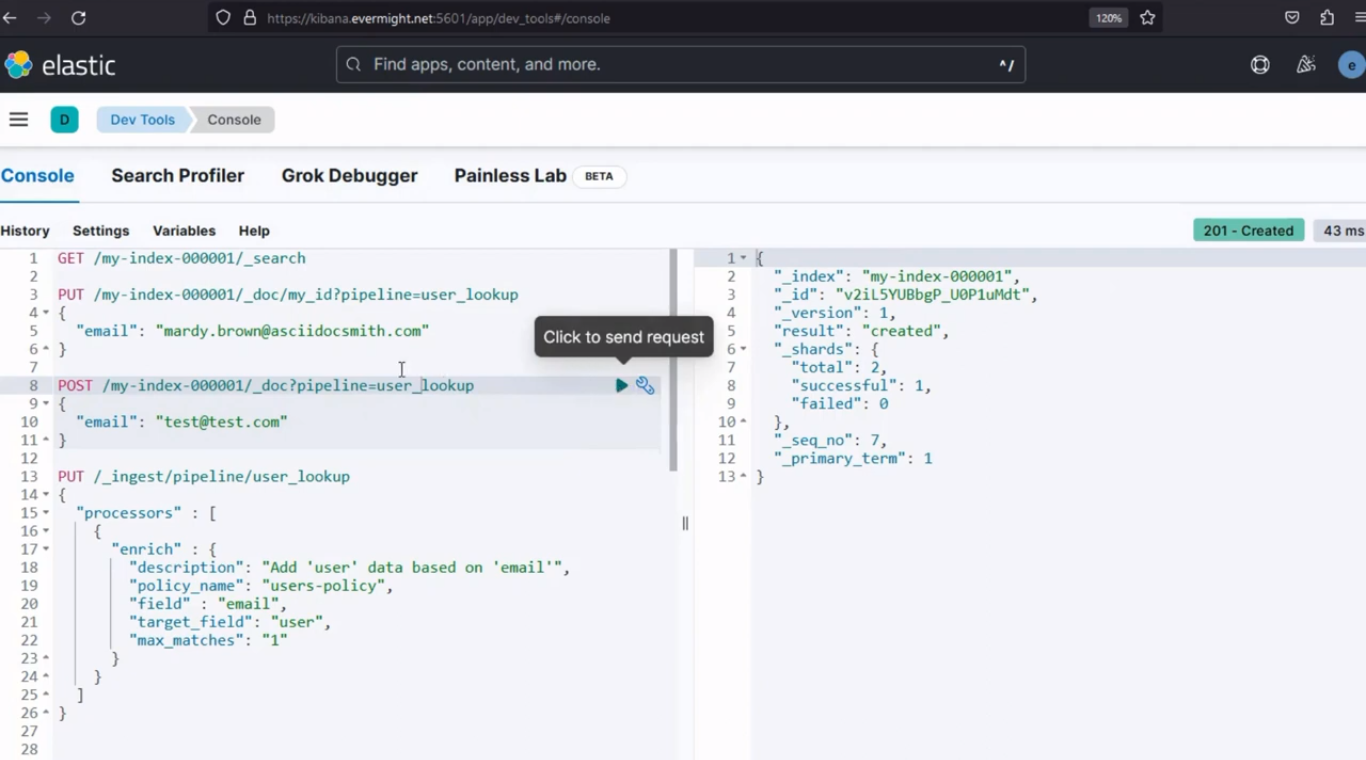 Konsolenergebnis für die Verwendung des POST-Befehls zum Einfügen eines Dokuments
Konsolenergebnis für die Verwendung des POST-Befehls zum Einfügen eines Dokuments
So reichern Sie Daten basierend auf „Range Value Match“ an [17:25]
Schritt 1: Einrichten eines Quellindex [17:33]
Gehen Sie in Kibana zu Entwicklertools > Konsole. Fügen Sie den folgenden Befehl in die Konsole ein:
PUT /networks
{
"mappings": {
"properties": {
"range": { "type": "ip_range" },
"name": { "type": "keyword" },
"department": { "type": "keyword" }
}
}
}
Sie sollten eine ähnliche Ausgabe wie im Bild unten erhalten:
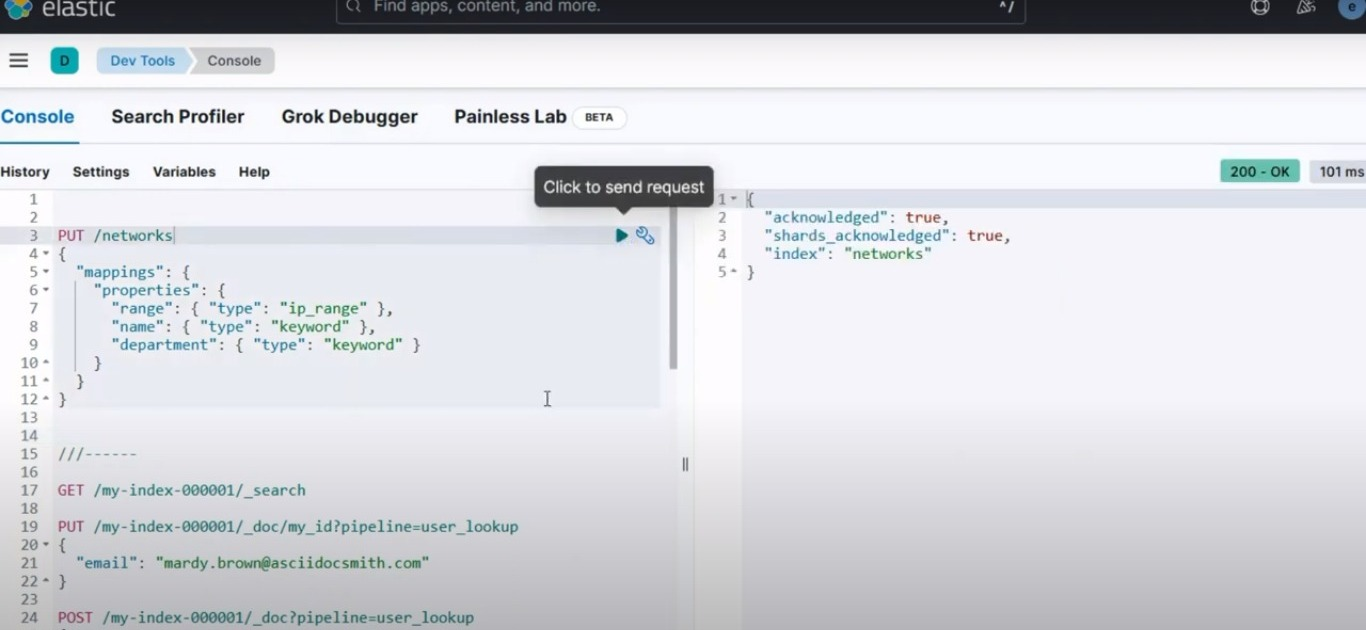 Konsolenergebnis zum Einrichten eines Indexes
Konsolenergebnis zum Einrichten eines Indexes
Schritt 2: Dokument in den Quellindex einfügen [20:10]
Führen Sie den folgenden Befehl aus, um ein Dokument in den erstellten Quellindex einzufügen
PUT /networks/_doc/1?refresh=wait_for
{
"range": "10.100.0.0/16",
"name": "production",
"department": "OPS"
}
Sie sollten ein Ergebnis wie das folgende erhalten:
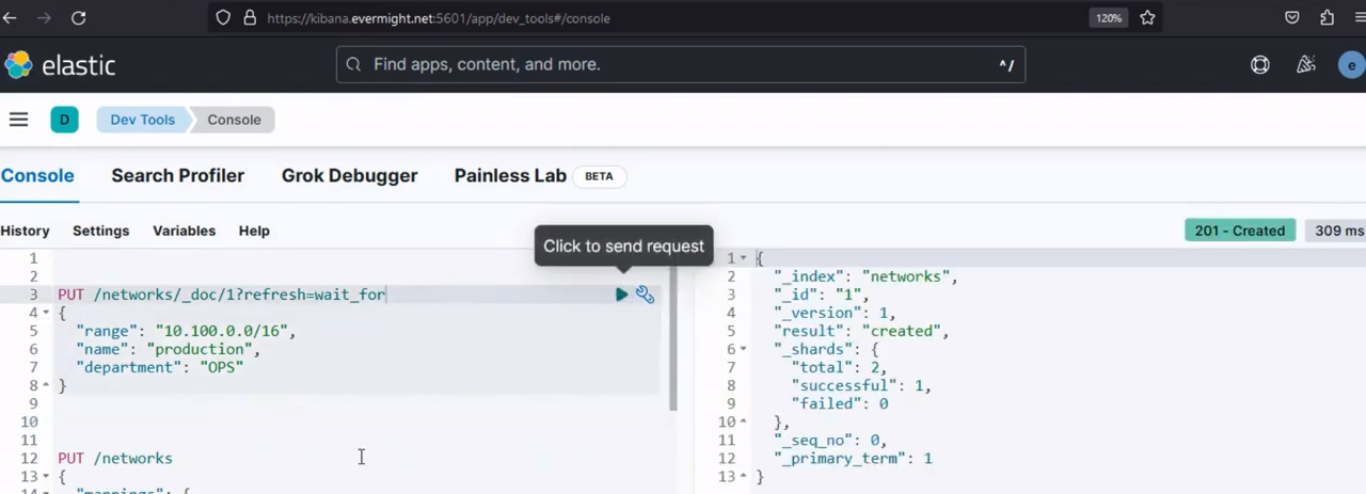 Konsolenergebnis zum Einfügen von Dokumenten in den Quellindex
Konsolenergebnis zum Einfügen von Dokumenten in den Quellindex
Schritt 3: Einrichten einer Anreicherungsrichtlinie [21:20]
Richten Sie die Anreicherungsrichtlinie mit dem folgenden Befehl ein:
PUT /_enrich/policy/networks-policy
{
"range": {
"indices": "networks",
"match_field": "range",
"enrich_fields": ["name", "department"]
}
}
Verwenden Sie den folgenden Befehl, um einen erweiterten Index für die Richtlinie zu erstellen.
POST /_enrich/policy/networks-policy/_execute?wait_for_completion=false
Nach dem Ausführen sollte ein ähnliches Ergebnis wie im Bild unten erscheinen.
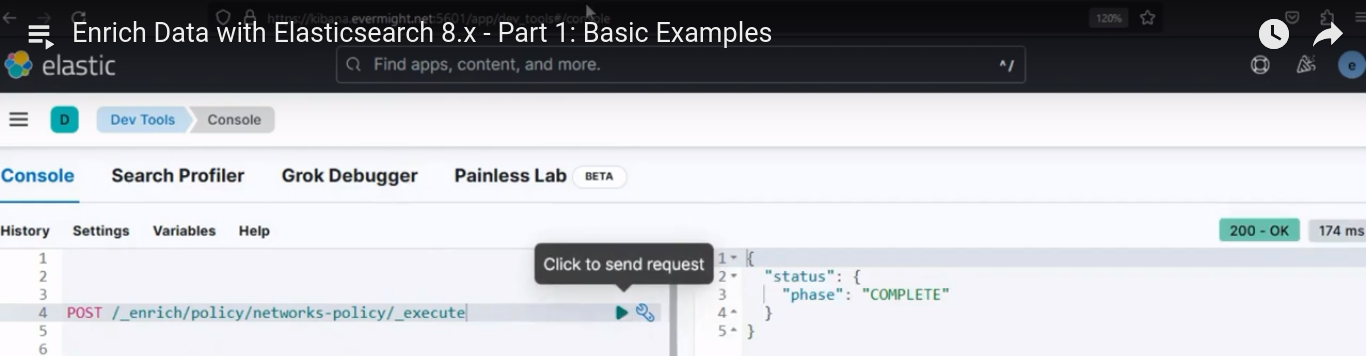 Konsolenergebnis für Schritt 3
Konsolenergebnis für Schritt 3
Um zu bestätigen, dass der Index erfolgreich angereichert wurde, gehen Sie zu Stapelverwaltung > Indexverwaltung, schalten Sie die Versteckte Indizes einschließen Schaltfläche „Ein“, dann Indizes neu laden.
Schritt 4: Erstellen einer Ingestion-Pipeline [22:58]
Erstellen Sie eine Aufnahmepipeline und fügen Sie einen Anreicherungsprozessor hinzu:
PUT /_ingest/pipeline/networks_lookup
{
"processors" : [
{
"enrich" : {
"description": "Add 'network' data based on 'ip'",
"policy_name": "networks-policy",
"field" : "ip",
"target_field": "network",
"max_matches": "10"
}
}
]
}
Verwenden Sie die unten stehende Ingest-Pipeline, um ein neues Dokument einzufügen. Das eingehende Dokument sollte das in Ihrem Anreicherungsprozessor angegebene Feld enthalten.
PUT /my-index-000001/_doc/my_id?pipeline=networks_lookup
{
"ip": "10.100.34.1"
}
Nach dem Ausführen sollte ein ähnliches Ergebnis wie im Bild unten erscheinen.
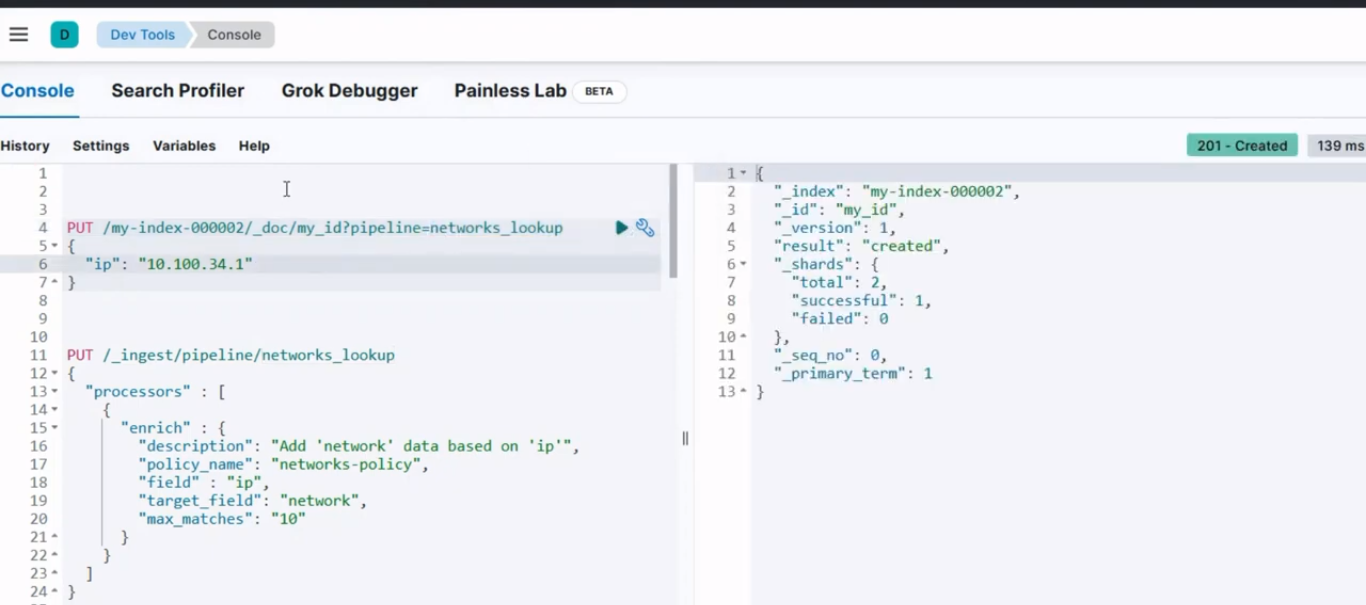 Konsolenergebnis für Schritt 4
Konsolenergebnis für Schritt 4
Und wenn Sie eine GET-Anfrage durchführen, sehen Sie das Ergebnis:
GET /my-index-000001/_doc/my_id
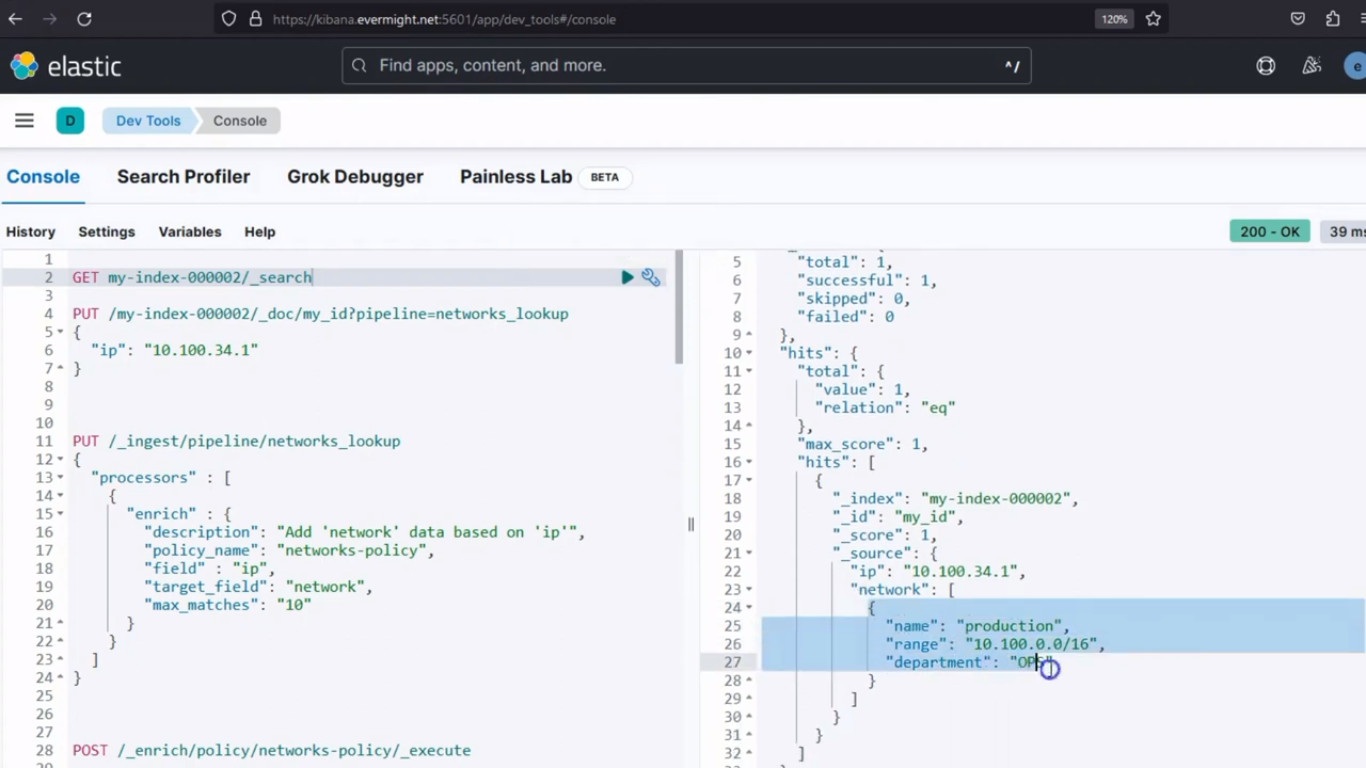 Konsolenergebnis für Dokumente
Konsolenergebnis für Dokumente
So reichern Sie Daten basierend auf „Geolocation Match“ an [25:23]
Schritt 1: Einrichten eines Quellindex [26:10]
Gehen Sie in Kibana zu Entwicklertools > Konsole. Fügen Sie den folgenden Befehl in die Konsole ein:
PUT /postal_codes
{
"mappings": {
"properties": {
"location": {
"type": "geo_shape"
},
"postal_code": {
"type": "keyword"
}
}
}
}
Sie sollten eine ähnliche Ausgabe wie im Bild unten erhalten:
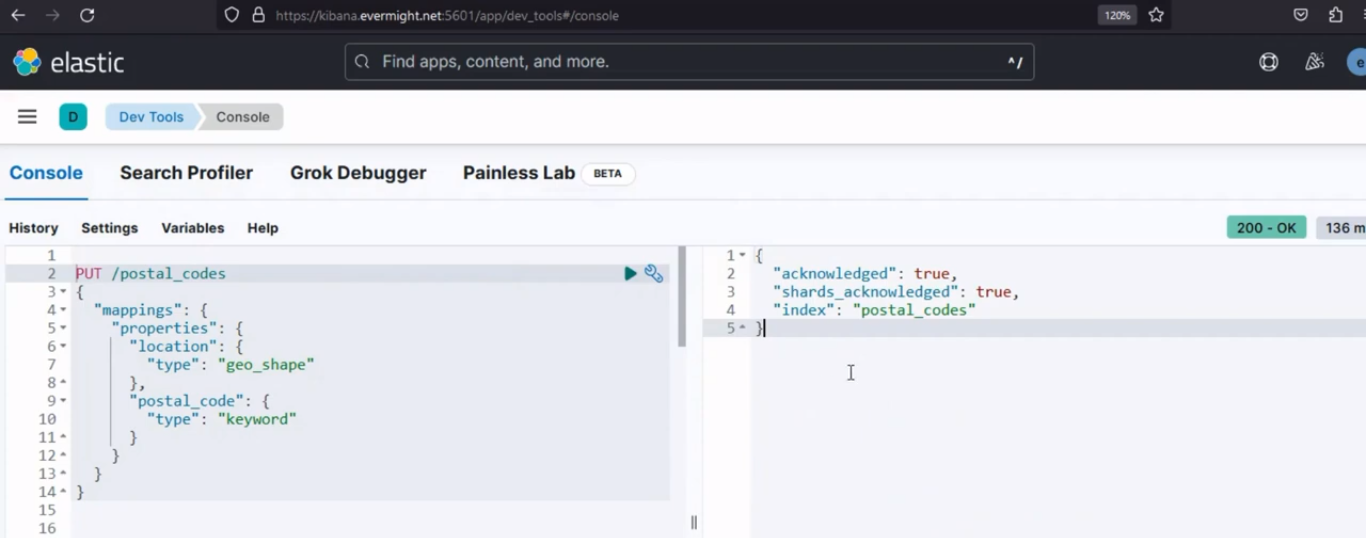 Konsolenergebnis zum Einrichten eines Indexes
Konsolenergebnis zum Einrichten eines Indexes
Schritt 2: Dokument in den Quellindex einfügen [27:00]
Indexieren Sie angereicherte Daten in den Quellindex, indem Sie den folgenden Befehl verwenden:
PUT /postal_codes/_doc/1?refresh=wait_for
{
"location": {
"type": "envelope",
"coordinates": [[13.0, 53.0], [14.0, 52.0]]
},
"postal_code": "96598"
}
Sie sollten ein Ergebnis wie das folgende erhalten:
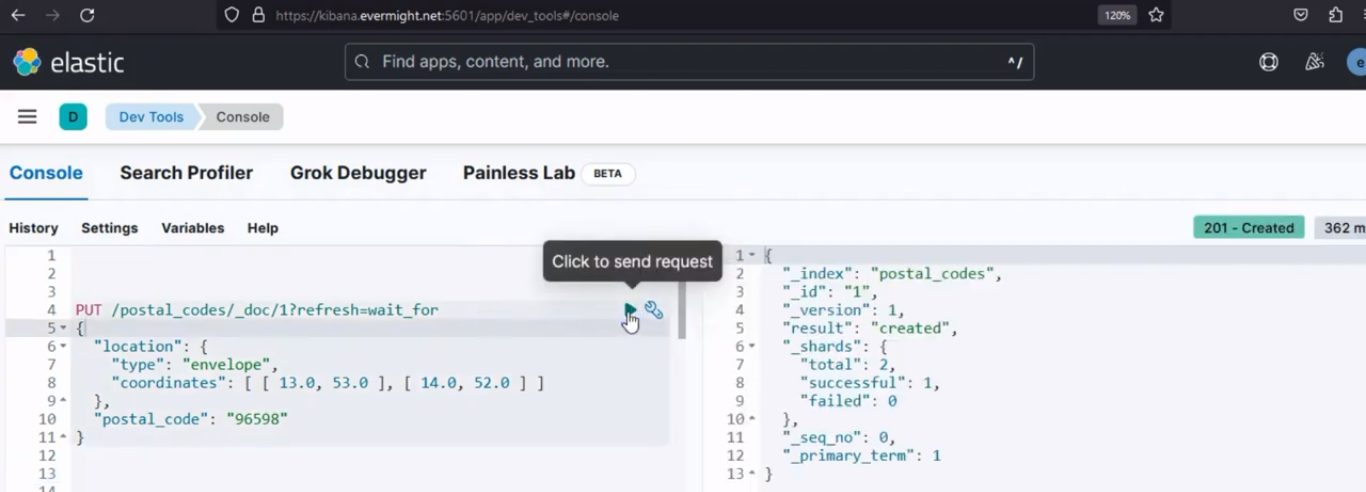 Konsolenergebnis zum Einfügen von Dokumenten in den Quellindex
Konsolenergebnis zum Einfügen von Dokumenten in den Quellindex
Schritt 3: Einrichten einer Anreicherungsrichtlinie [27:38]
Richten Sie die Anreicherungsrichtlinie mit dem folgenden Befehl ein:
PUT /_enrich/policy/postal_policy
{
"geo_match": {
"indices": "postal_codes",
"match_field": "location",
"enrich_fields": [ "location", "postal_code" ]
}
}
Verwenden Sie den folgenden Befehl, um einen erweiterten Index für die Richtlinie zu erstellen.
POST /_enrich/policy/postal_policy/_execute?wait_for_completion=false
Nach dem Ausführen sollte ein ähnliches Ergebnis wie im Bild unten erscheinen.
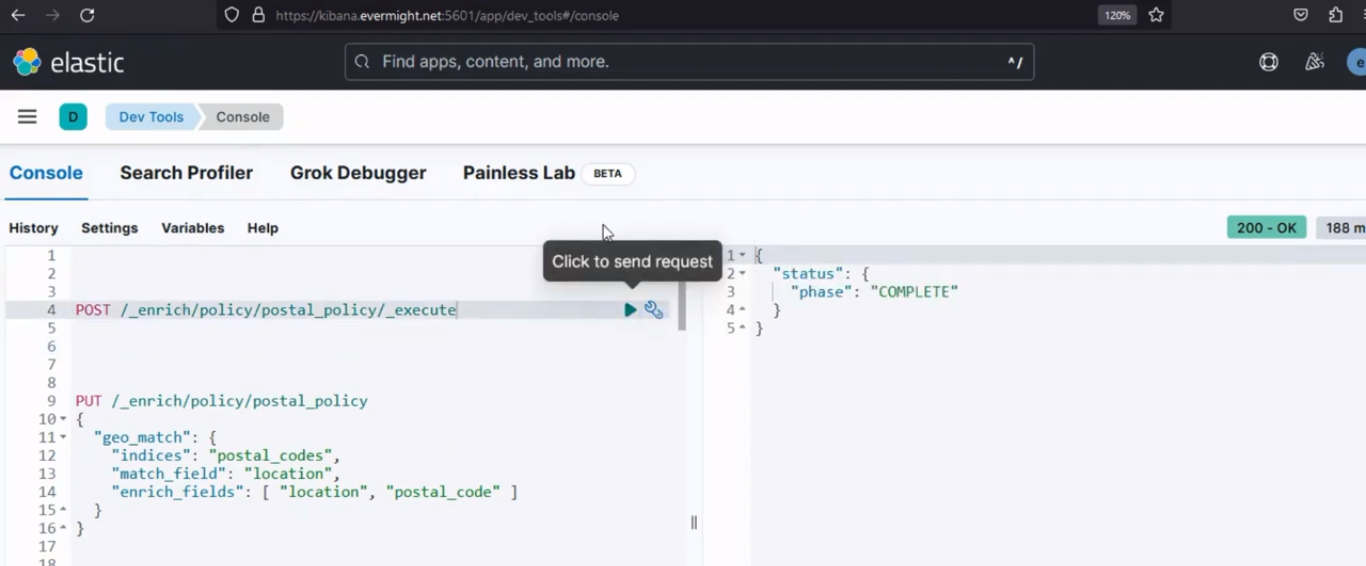 Konsolenergebnis für Schritt 3
Konsolenergebnis für Schritt 3
Um zu bestätigen, dass der Index erfolgreich angereichert wurde, gehen Sie zu Stapelverwaltung > Indexverwaltung, schalten Sie die Versteckte Indizes einschließen Schaltfläche „Ein“, dann Indizes neu laden.
Schritt 4: Erstellen einer Ingestion-Pipeline [28:51]
Erstellen Sie eine Aufnahmepipeline und fügen Sie einen Anreicherungsprozessor hinzu:
PUT /_ingest/pipeline/postal_lookup
{
"processors": [
{
"enrich": {
"description": "Add 'geo_data' based on 'geo_location'",
"policy_name": "postal_policy",
"field": "geo_location",
"target_field": "geo_data",
"shape_relation": "INTERSECTS"
}
}
]
}
Verwenden Sie die unten stehende Ingest-Pipeline, um ein neues Dokument einzufügen. Das eingehende Dokument sollte das in Ihrem Anreicherungsprozessor angegebene Feld enthalten.
PUT /users2/_doc/0?pipeline=postal_lookup
{
"first_name": "Mardy",
"last_name": "Brown",
"geo_location": "POINT (13.5 52.5)"
}
Nach dem Ausführen sollte ein ähnliches Ergebnis wie im Bild unten erscheinen.
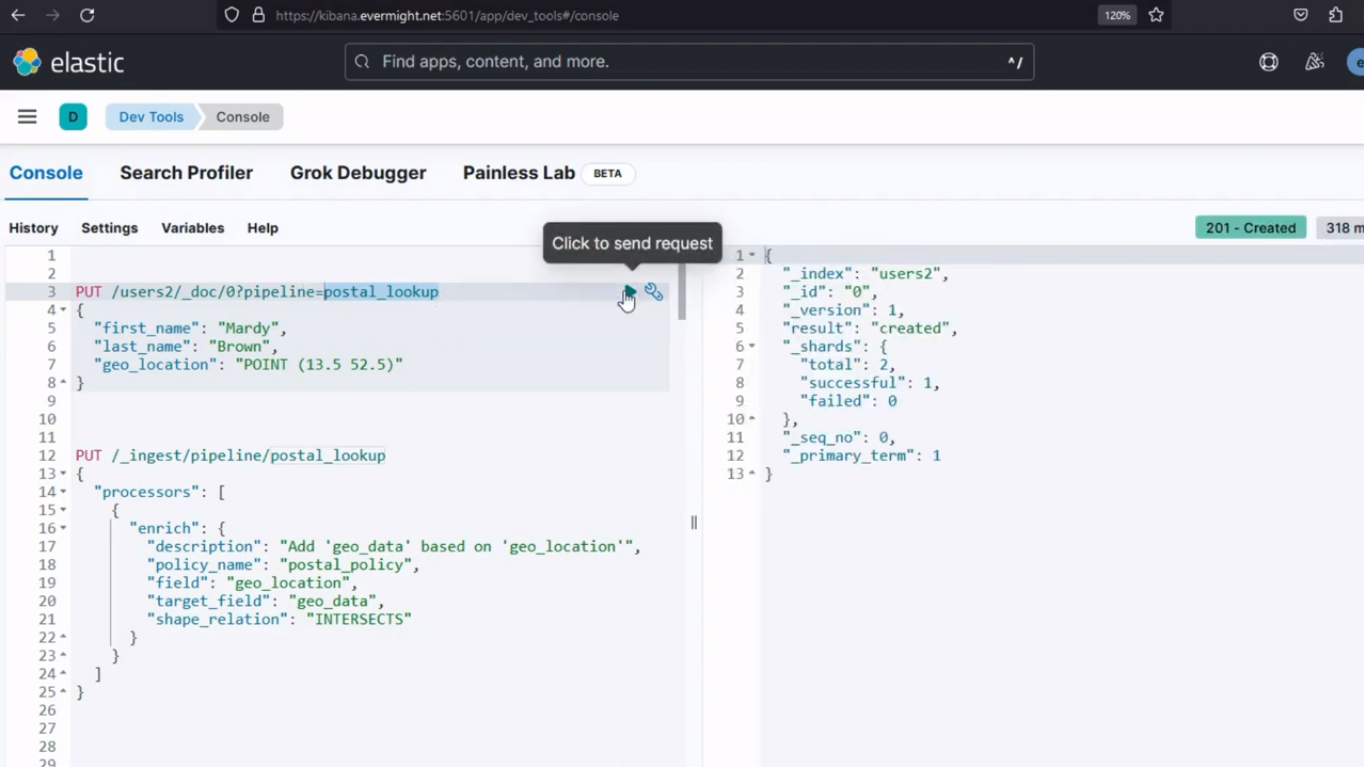 Konsolenergebnis für Schritt 4
Konsolenergebnis für Schritt 4
Und wenn Sie eine GET-Anfrage durchführen, sehen Sie das Ergebnis:
GET /users2/_search
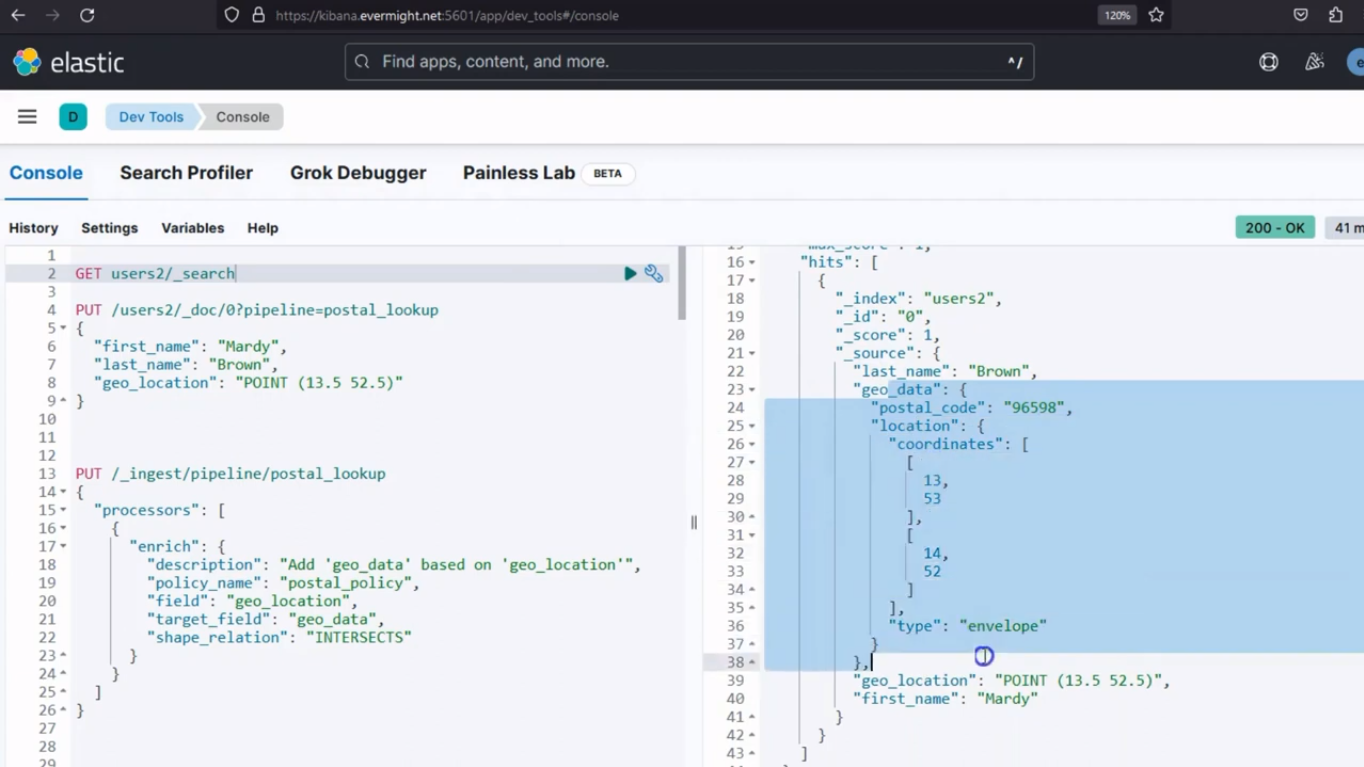 Konsolenergebnis für Dokumente
Konsolenergebnis für Dokumente