
Introducción
Código en Github: Enriquecimiento de datos de Elasticsearch
Si aún no tiene Elasticsearch y Kibana configurados, entonces siga estas instrucciones.
Este vídeo asume que estás usando Certificados firmados públicamente. Si estas usando Certificados autofirmados, Vaya aquí Por determinar.
Requisitos
- Una instancia en ejecución de Elasticsearch y Kibana.
- Una instancia de otro servidor Ubuntu 20.04 que ejecuta cualquier tipo de servicio.
Proceso
Definición de enriquecimiento de datos [00:09]
Vaya a la marca de tiempo específica en el video para comprender más sobre lo que significa el enriquecimiento de datos.
Cómo enriquecer datos según la "coincidencia de valores exactos" [05:47]
Paso 1: Configurar un índice de origen [06:22]
En Kibana, vaya a Herramientas de desarrollo > Consola. Pegue el siguiente comando en la consola. Al ejecutarlo, Elasticsearch creará automáticamente un nuevo índice, le agregará estos datos y realizará un mapeo automático para cada campo.
PUT /users/_doc/1?refresh=wait_for
{
"email": "mardy.brown@asciidocsmith.com",
"first_name": "Mardy",
"last_name": "Brown",
"city": "New Orleans",
"county": "Orleans",
"state": "LA",
"zip": 70116,
"web": "mardy.asciidocsmith.com"
}
Después de ejecutarlo, debería producir un resultado similar a la imagen de abajo;
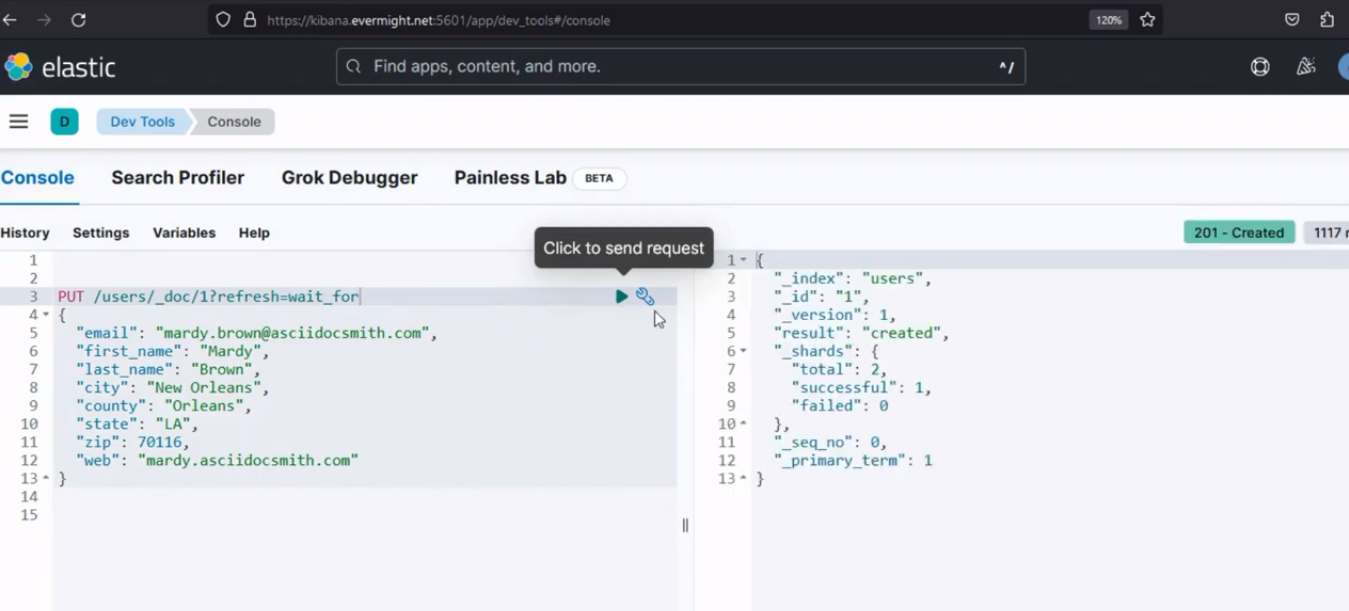 Resultado de la consola para el paso 1
Resultado de la consola para el paso 1
Para confirmar que el índice se creó correctamente, vaya a Gestión de pilas > Gestión de índices. Deberías ver un resultado similar al de la imagen de abajo:
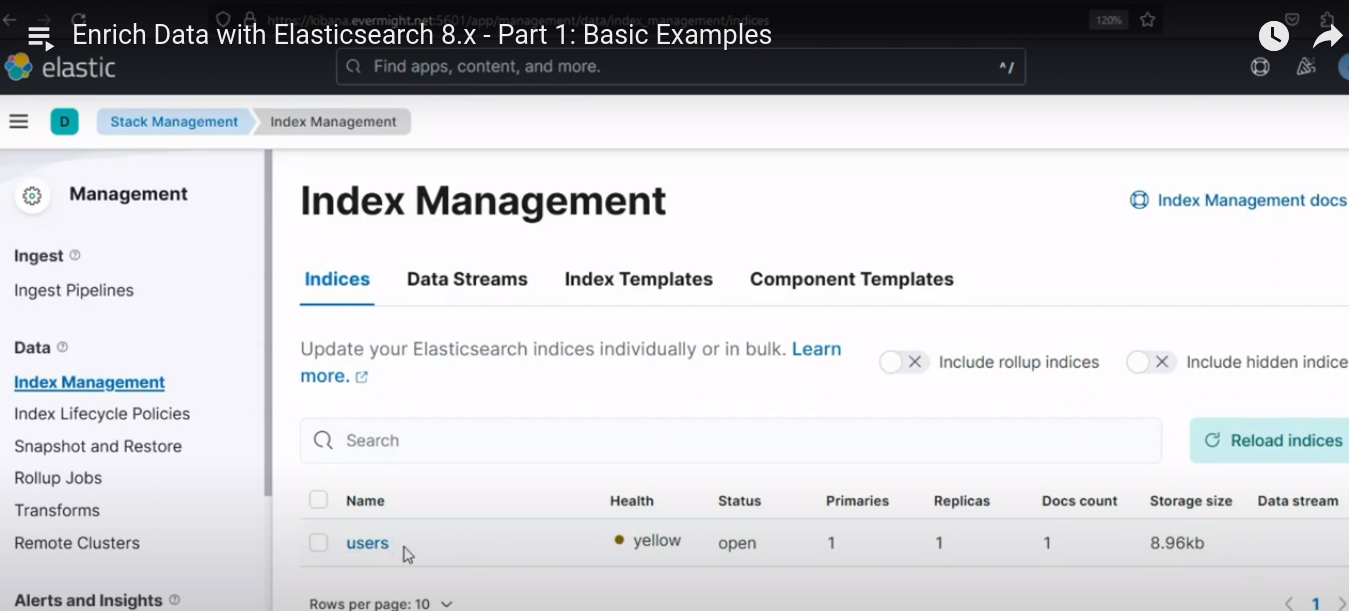 Índice creado exitosamente
Índice creado exitosamente
Paso 2: Configurar una política de enriquecimiento [07:58]
En Kibana, vaya a Herramientas de desarrollo > Consola. Pegue el siguiente comando en la consola y, al ejecutar este comando de política, esta dará instrucciones sobre cómo completar los datos entrantes con datos del índice de origen.
PUT /_enrich/policy/users-policy
{
"match": {
"indices": "users",
"match_field": "email",
"enrich_fields": ["first_name", "last_name", "city", "zip", "state"]
}
}
Utilice el siguiente comando para crear un índice enriquecido para la política.
POST /_enrich/policy/users-policy/_execute?wait_for_completion=false
Después de ejecutarlo, debería producir un resultado similar a la imagen de abajo;
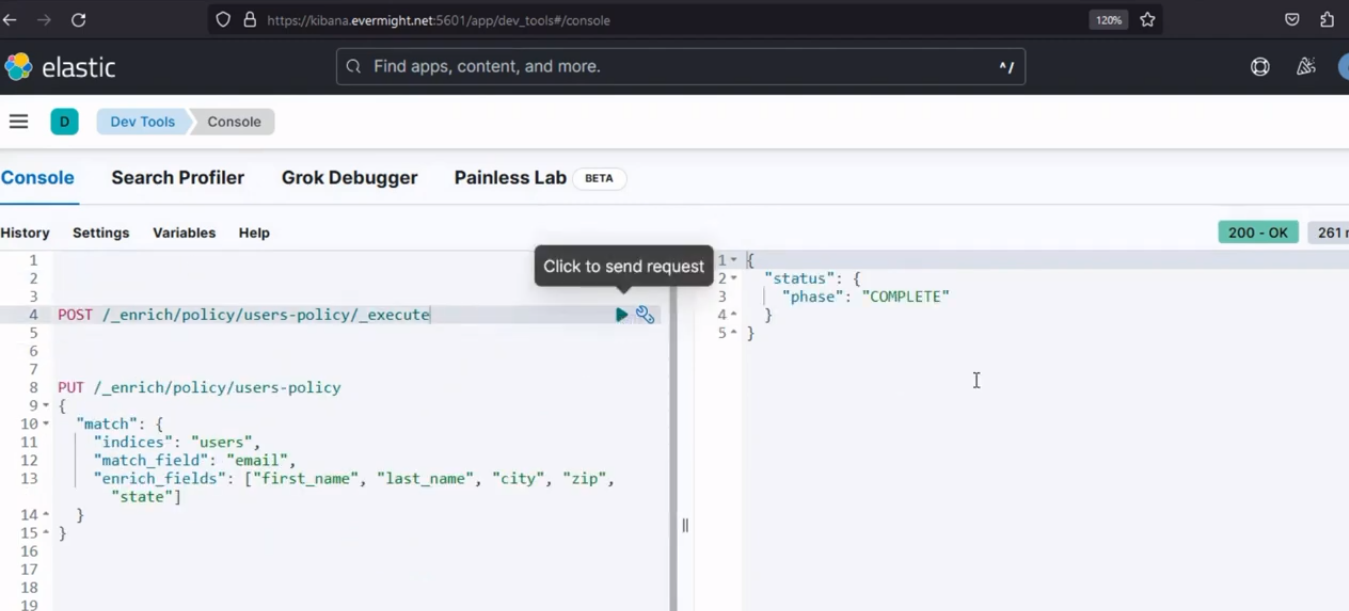 Resultado de la consola para el paso 2
Resultado de la consola para el paso 2
Para confirmar que el índice se enriqueció correctamente, vaya a Gestión de pilas > Gestión de índices, alternar el incluir índices ocultos Activa el botón y recarga los índices. Deberías ver un resultado similar al de la imagen a continuación:
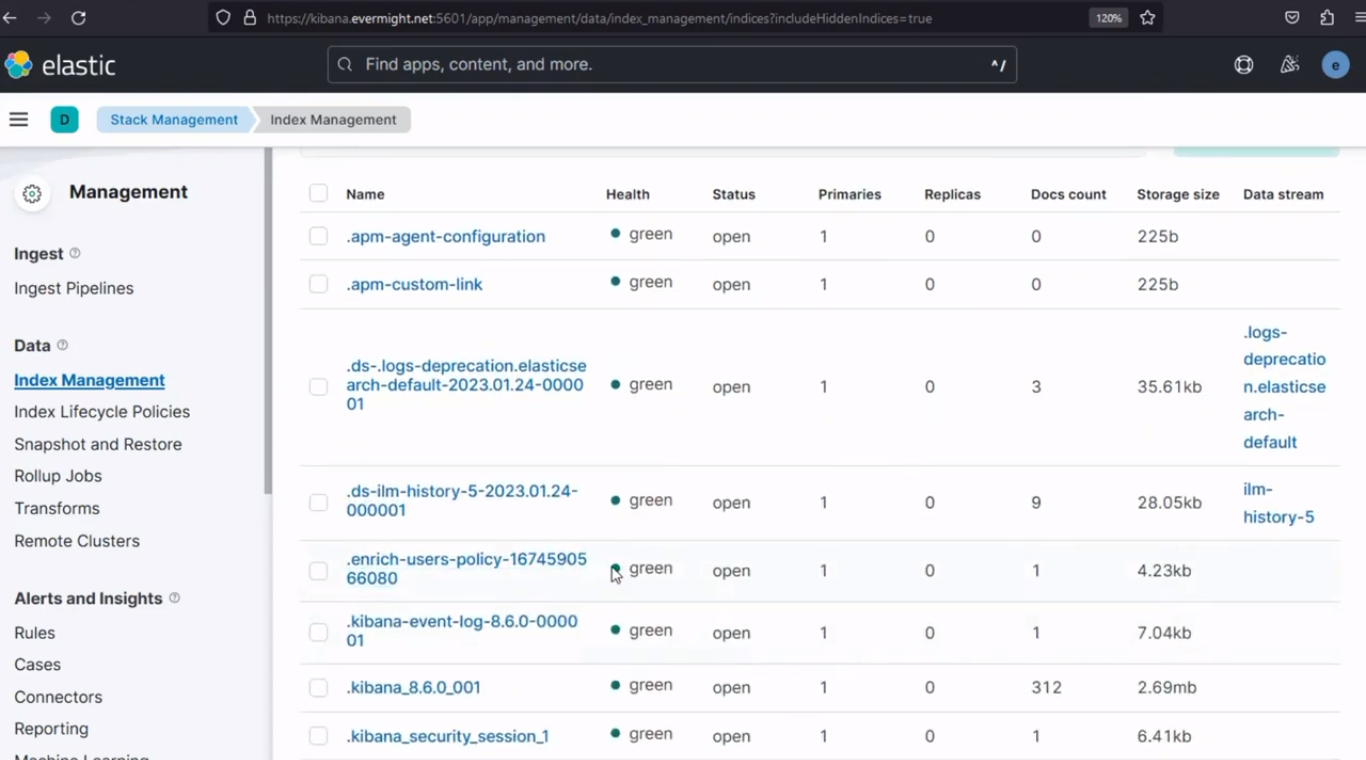 Índice enriquecido con éxito
Índice enriquecido con éxito
Paso 3: Configurar una canalización de ingestión [11:05]
Cree una canalización de ingesta con un procesador de enriquecimiento. Use el siguiente comando para ello:
PUT /_ingest/pipeline/user_lookup
{
"processors" : [
{
"enrich" : {
"description": "Add 'user' data based on 'email'",
"policy_name": "users-policy",
"field" : "email",
"target_field": "user",
"max_matches": "1"
}
}
]
}
Después de ejecutarlo, debería producir un resultado similar a la imagen de abajo;
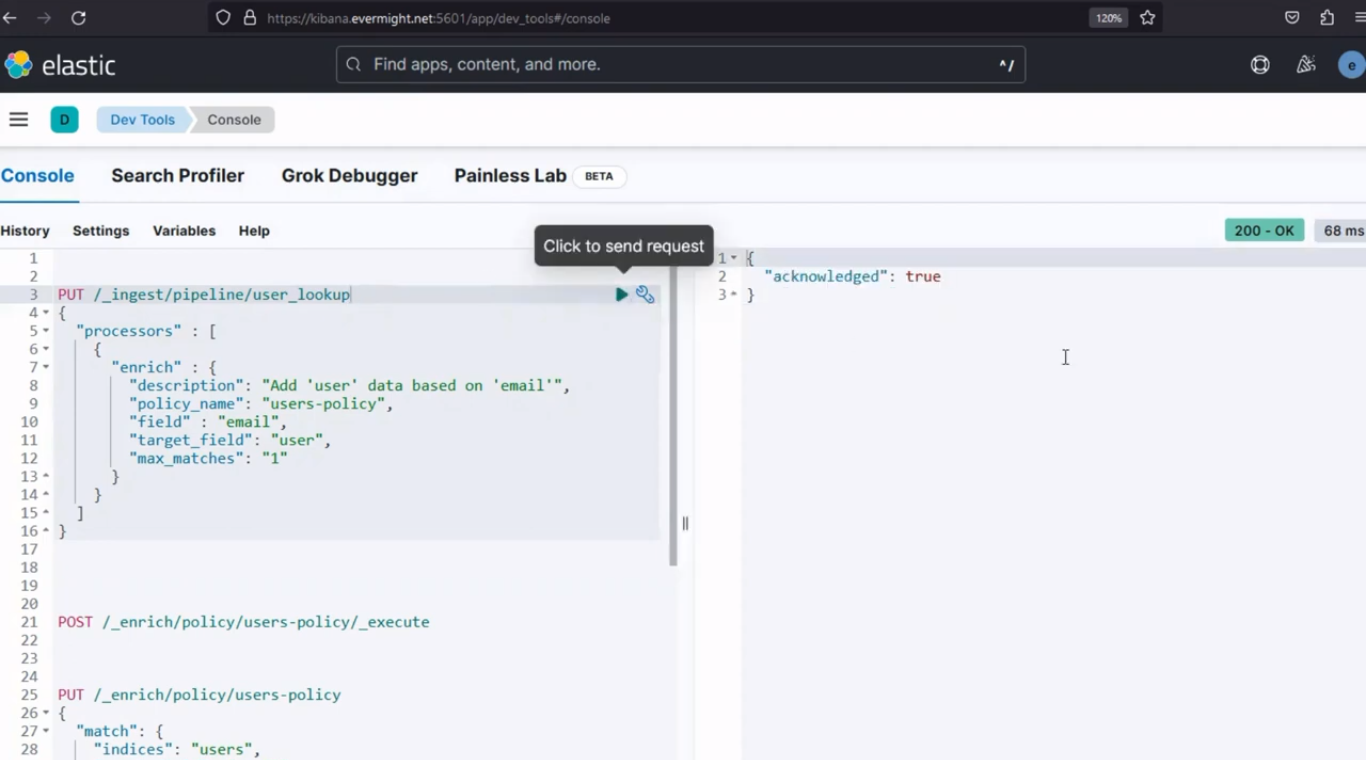 Resultado de la consola para el paso 3
Resultado de la consola para el paso 3
Para confirmar que el índice para la canalización de ingesta se realizó correctamente, vaya a Gestión de pilas > Canalizaciones de ingesta. Deberías ver un resultado similar al de la imagen de abajo:
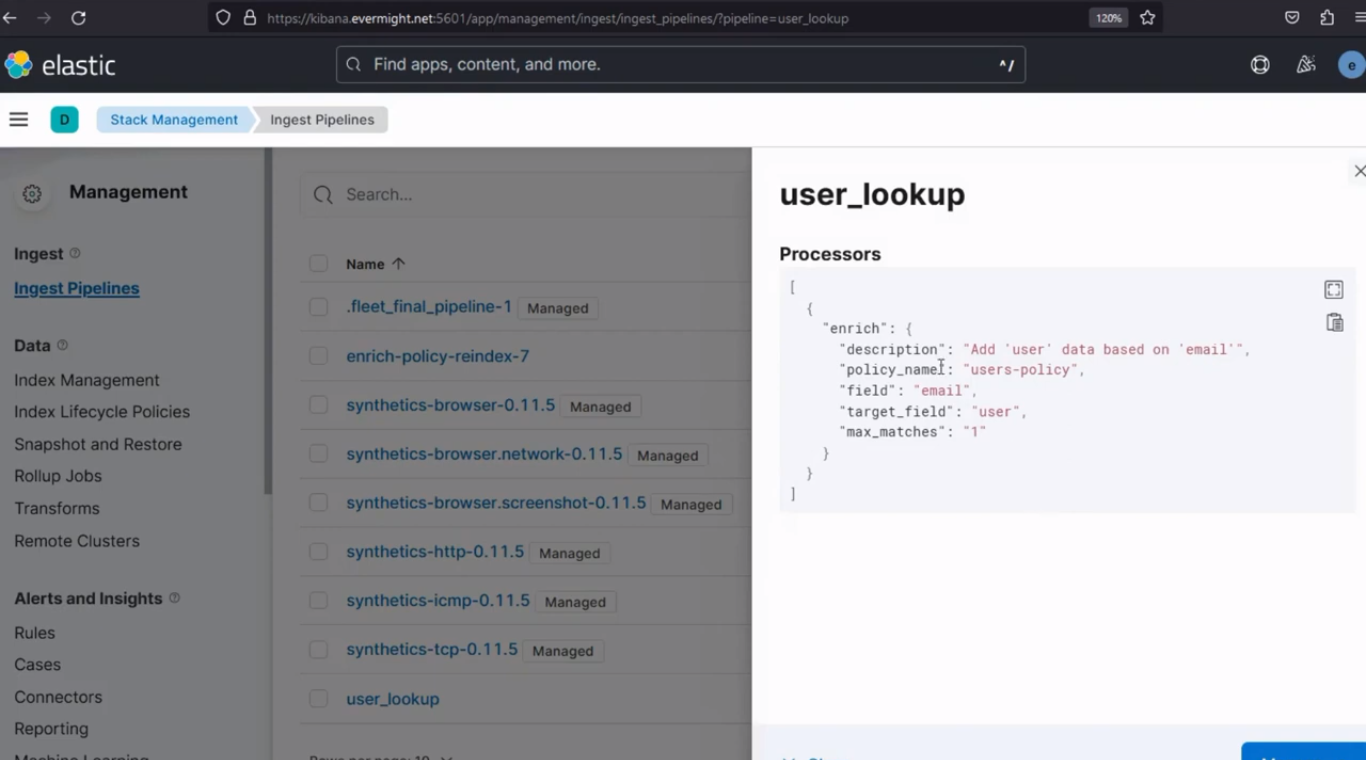 Índice de canalización de ingesta creado correctamente
Índice de canalización de ingesta creado correctamente
Paso 4: Insertar documento mediante la canalización de ingestión [13:16]
Utilice la siguiente canalización de ingesta para insertar un nuevo documento. El documento entrante debe incluir el campo especificado en su procesador de enriquecimiento.
PUT /my-index-000001/_doc/my_id?pipeline=user_lookup
{
"email": "mardy.brown@asciidocsmith.com"
}
Después de ejecutarlo, debería producir un resultado similar a la imagen de abajo;
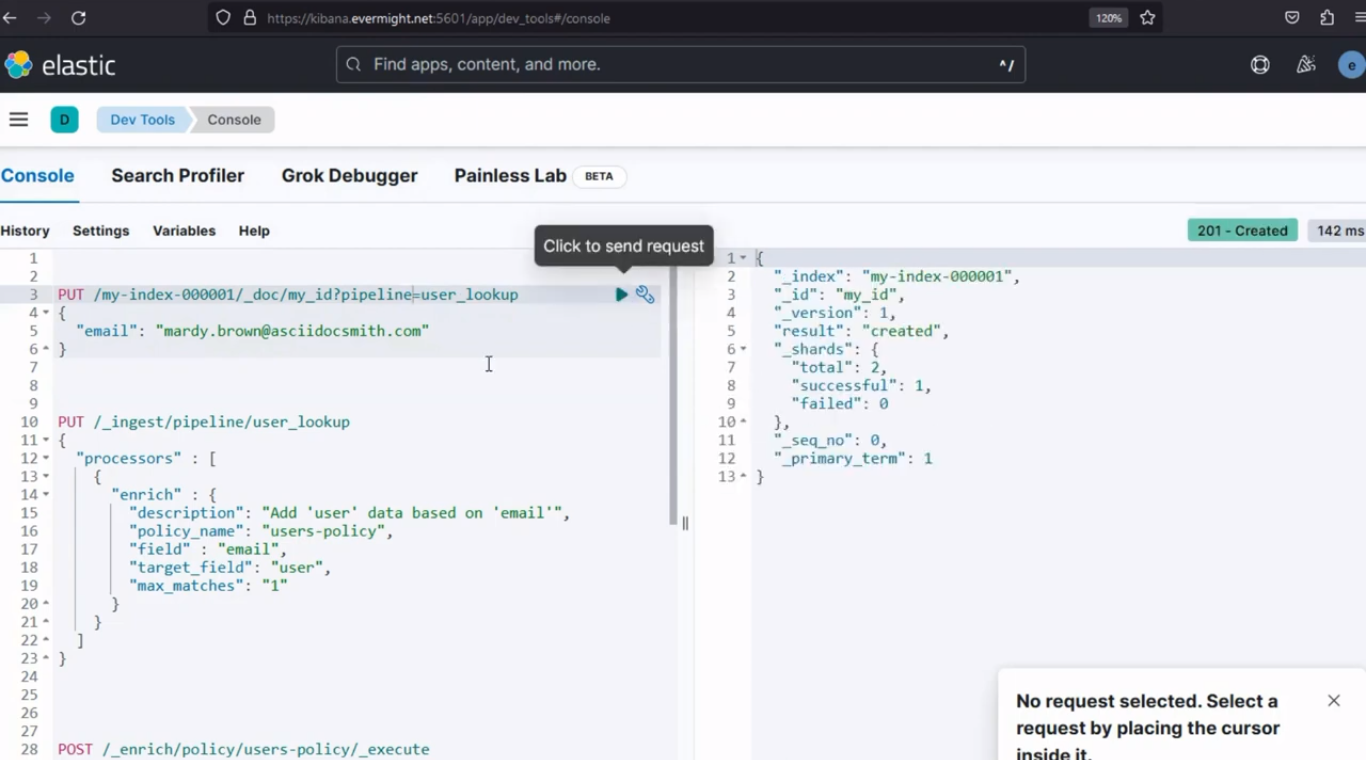 Resultado de la consola para el paso 4
Resultado de la consola para el paso 4
Y cuando realices una solicitud GET, verás el resultado:
GET /my-index-000001/_doc/my_id
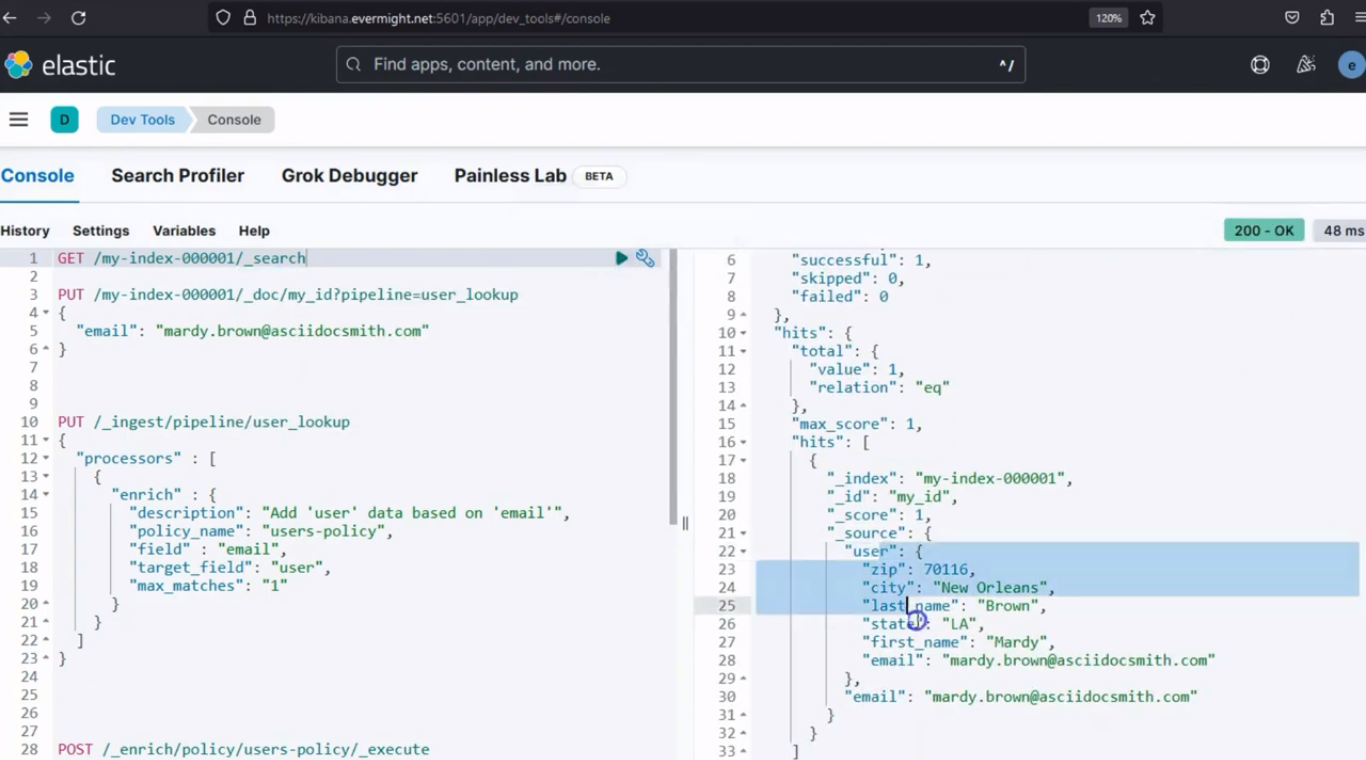 Resultado de la consola para documentos
Resultado de la consola para documentos
Insertemos otro documento en el índice fuente.
POST /users/_doc
{
"email": "test@test.com",
"first_name": "Test",
"last_name": "Brown",
"city": "New Orleans",
"county": "Orleans",
"state": "LA",
"zip": 70116,
"web": "mardy.asciidocsmith.com"
}
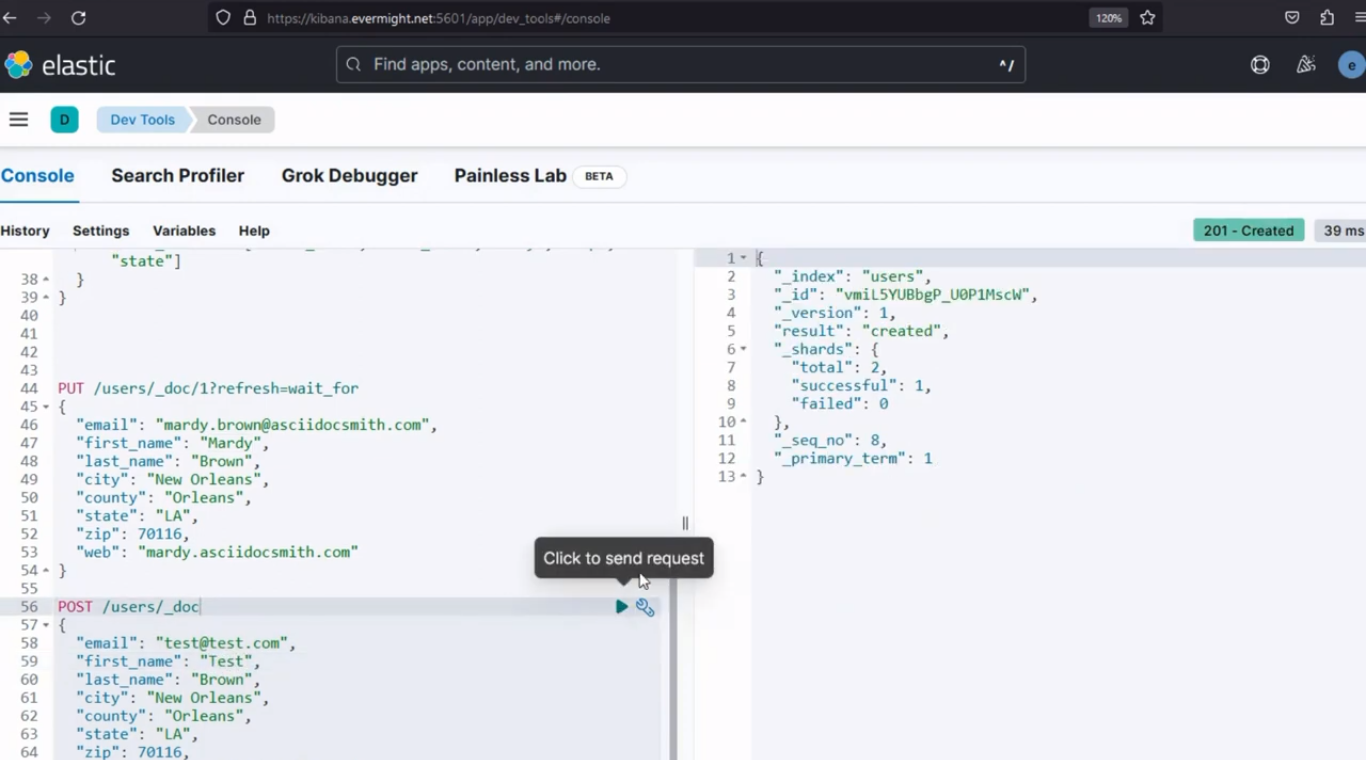 Resultado de la consola para insertar un nuevo documento en el índice de origen
Resultado de la consola para insertar un nuevo documento en el índice de origen
Luego ejecute el siguiente comando:
PUT /my-index-000001/_doc/pipeline=user_lookup
{
"email": "test@test.com"
}
Después de ejecutarlo, debería producir un resultado similar a la imagen de abajo;
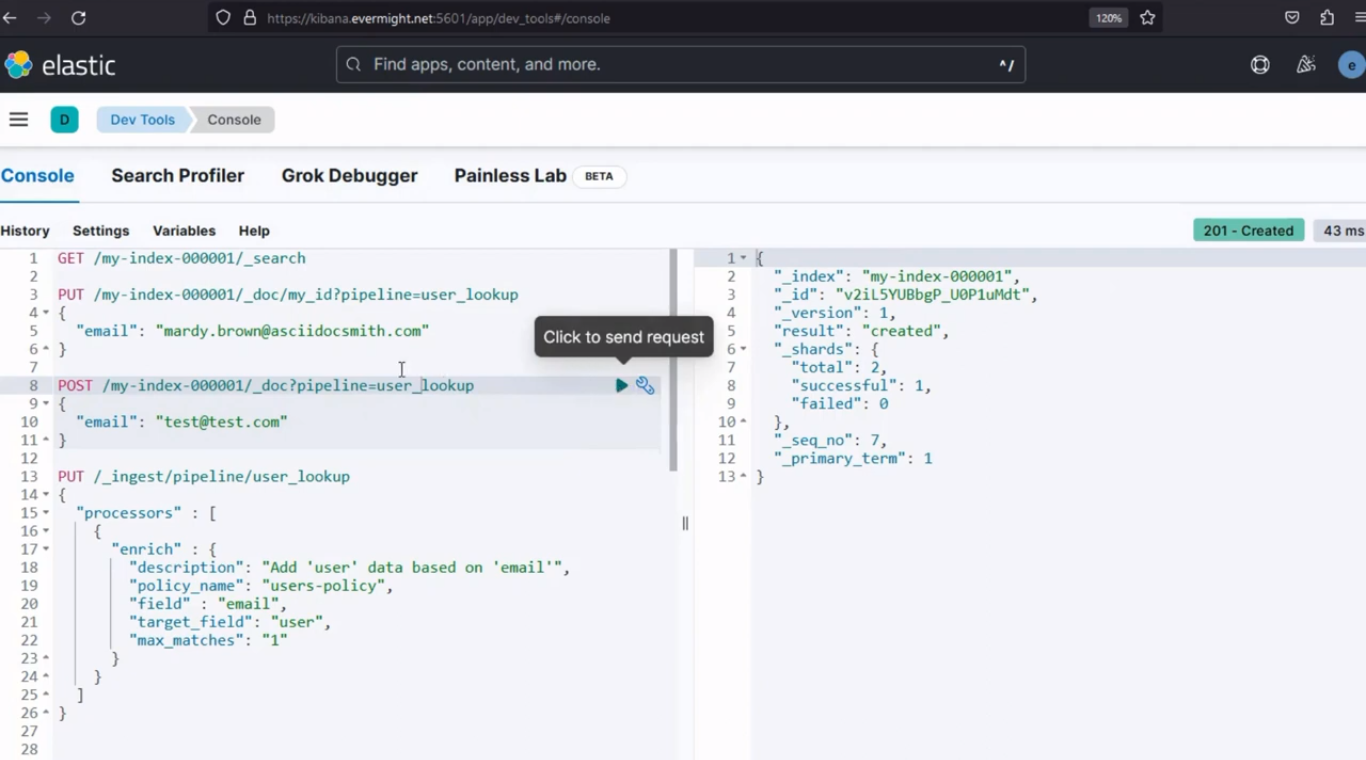 Resultado de la consola al usar el comando POST para insertar un documento
Resultado de la consola al usar el comando POST para insertar un documento
Cómo enriquecer datos según la "coincidencia de rangos" [17:25]
Paso 1: Configurar un índice de origen [17:33]
En Kibana, vaya a Herramientas de desarrollo > Consola. Pegue el siguiente comando en la consola:
PUT /networks
{
"mappings": {
"properties": {
"range": { "type": "ip_range" },
"name": { "type": "keyword" },
"department": { "type": "keyword" }
}
}
}
Debería obtener un resultado similar a la imagen a continuación:
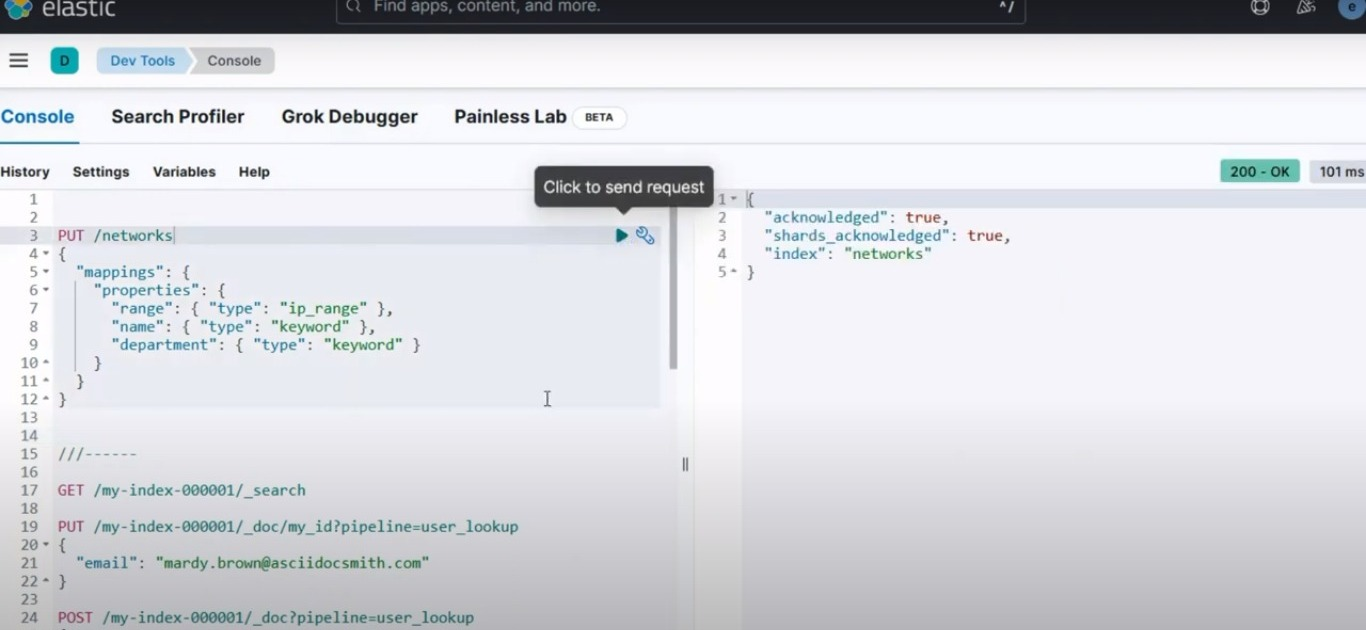 Resultado de la consola para configurar un índice
Resultado de la consola para configurar un índice
Paso 2: Insertar documento en el índice de origen [20:10]
Ejecute el siguiente comando para insertar un documento en el índice de origen que se creó
PUT /networks/_doc/1?refresh=wait_for
{
"range": "10.100.0.0/16",
"name": "production",
"department": "OPS"
}
Deberías obtener un resultado como este:
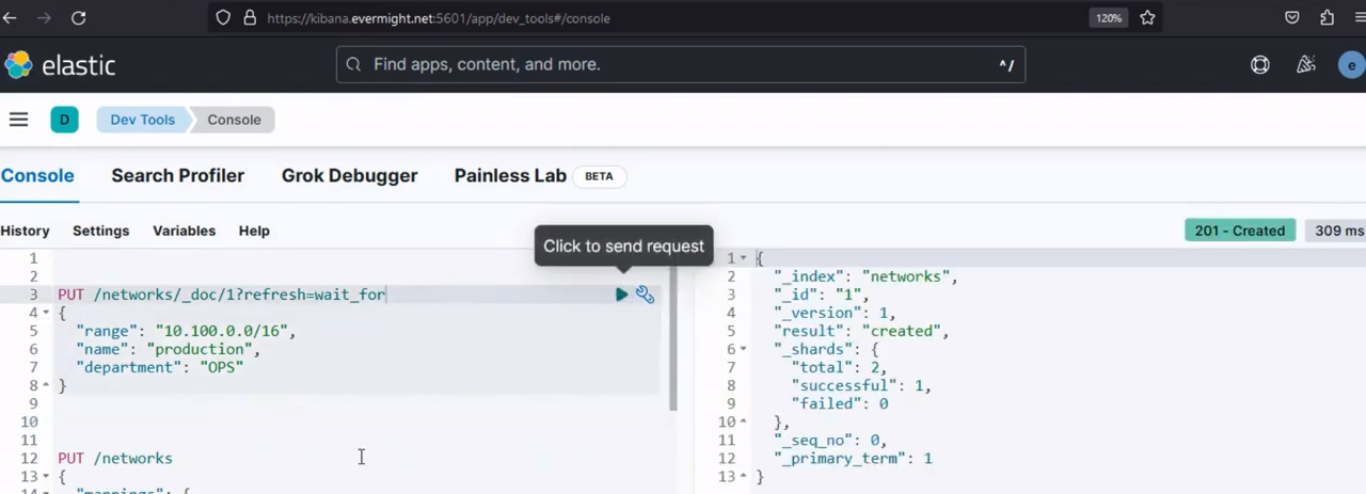 Resultado de la consola para insertar documentos en el índice de origen
Resultado de la consola para insertar documentos en el índice de origen
Paso 3: Establecer una política de enriquecimiento [21:20]
Configure la política de enriquecimiento con el siguiente comando:
PUT /_enrich/policy/networks-policy
{
"range": {
"indices": "networks",
"match_field": "range",
"enrich_fields": ["name", "department"]
}
}
Utilice el siguiente comando para crear un índice enriquecido para la política.
POST /_enrich/policy/networks-policy/_execute?wait_for_completion=false
Después de ejecutarlo, debería producir un resultado similar a la imagen de abajo;
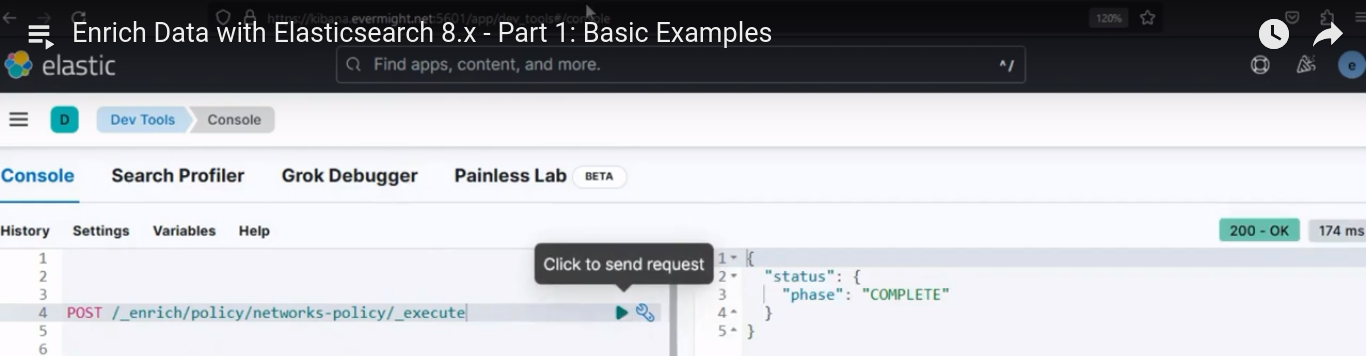 Resultado de la consola para el paso 3
Resultado de la consola para el paso 3
Para confirmar que el índice se enriqueció correctamente, vaya a Gestión de pilas > Gestión de índices, alternar el incluir índices ocultos Botón Activado, luego recargar índices.
Paso 4: Crear una canalización de ingestión [22:58]
Cree una canalización de ingesta y agregue un procesador de enriquecimiento:
PUT /_ingest/pipeline/networks_lookup
{
"processors" : [
{
"enrich" : {
"description": "Add 'network' data based on 'ip'",
"policy_name": "networks-policy",
"field" : "ip",
"target_field": "network",
"max_matches": "10"
}
}
]
}
Utilice la siguiente canalización de ingesta para insertar un nuevo documento. El documento entrante debe incluir el campo especificado en su procesador de enriquecimiento.
PUT /my-index-000001/_doc/my_id?pipeline=networks_lookup
{
"ip": "10.100.34.1"
}
Después de ejecutarlo, debería producir un resultado similar a la imagen de abajo;
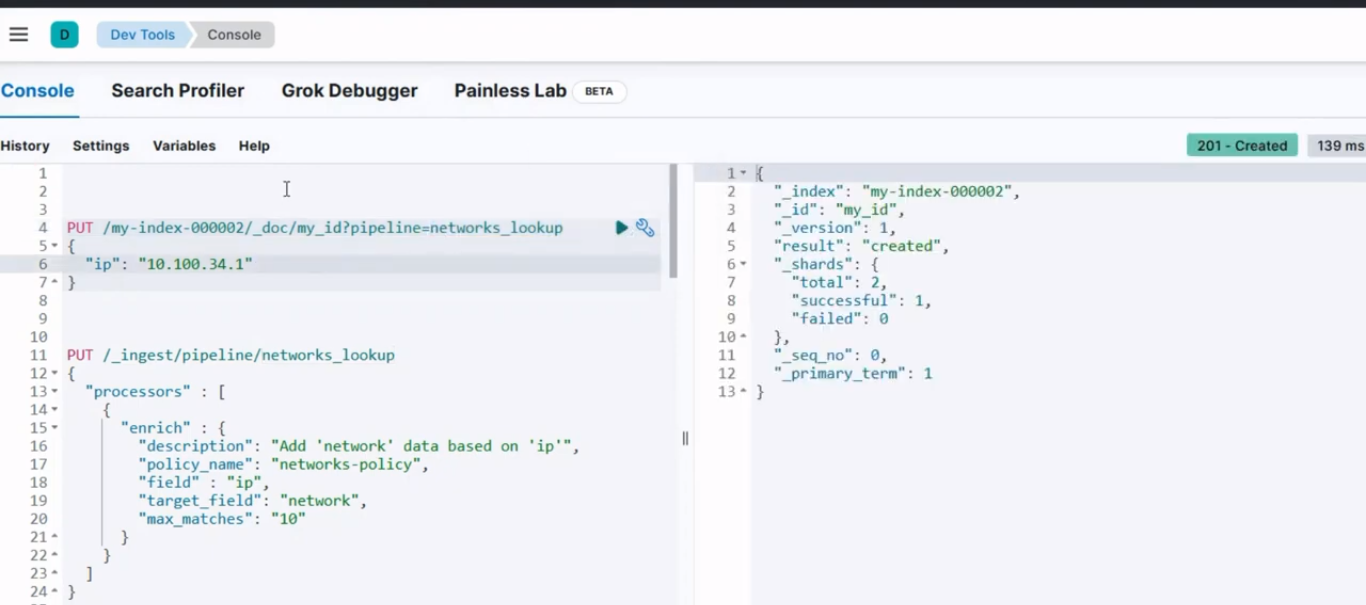 Resultado de la consola para el paso 4
Resultado de la consola para el paso 4
Y cuando realices una solicitud GET, verás el resultado:
GET /my-index-000001/_doc/my_id
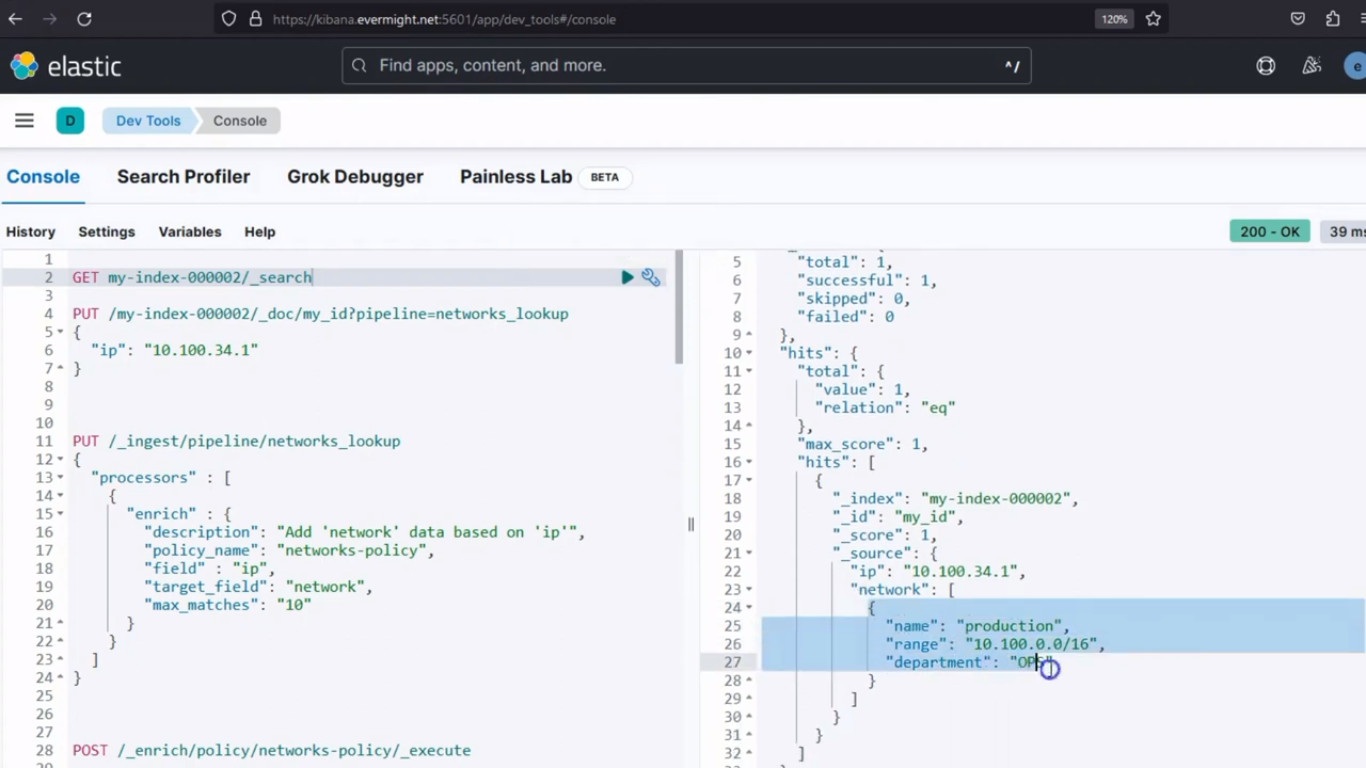 Resultado de la consola para documentos
Resultado de la consola para documentos
Cómo enriquecer datos según la "coincidencia de geolocalización" [25:23]
Paso 1: Configurar un índice de origen [26:10]
En Kibana, vaya a Herramientas de desarrollo > Consola. Pegue el siguiente comando en la consola:
PUT /postal_codes
{
"mappings": {
"properties": {
"location": {
"type": "geo_shape"
},
"postal_code": {
"type": "keyword"
}
}
}
}
Debería obtener un resultado similar a la imagen a continuación:
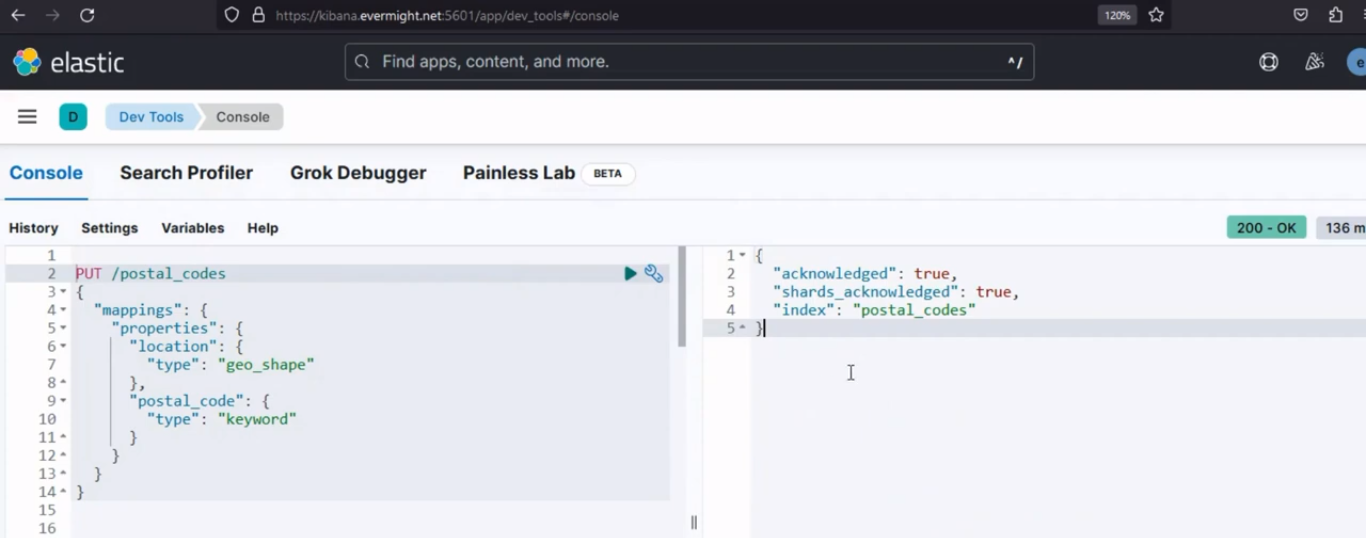 Resultado de la consola para configurar un índice
Resultado de la consola para configurar un índice
Paso 2: Insertar documento en el índice de origen [27:00]
Indexe los datos enriquecidos en el índice de origen, utilizando el siguiente comando:
PUT /postal_codes/_doc/1?refresh=wait_for
{
"location": {
"type": "envelope",
"coordinates": [[13.0, 53.0], [14.0, 52.0]]
},
"postal_code": "96598"
}
Deberías obtener un resultado como este:
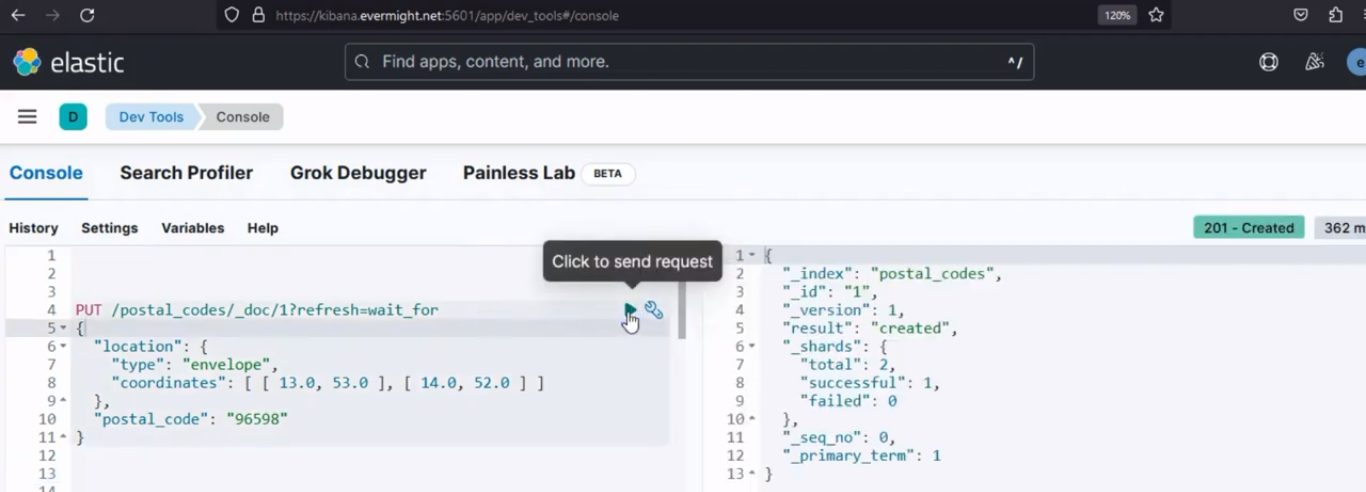 Resultado de la consola para insertar documentos en el índice de origen
Resultado de la consola para insertar documentos en el índice de origen
Paso 3: Configurar una política de enriquecimiento [27:38]
Configure la política de enriquecimiento con el siguiente comando:
PUT /_enrich/policy/postal_policy
{
"geo_match": {
"indices": "postal_codes",
"match_field": "location",
"enrich_fields": [ "location", "postal_code" ]
}
}
Utilice el siguiente comando para crear un índice enriquecido para la política.
POST /_enrich/policy/postal_policy/_execute?wait_for_completion=false
Después de ejecutarlo, debería producir un resultado similar a la imagen de abajo;
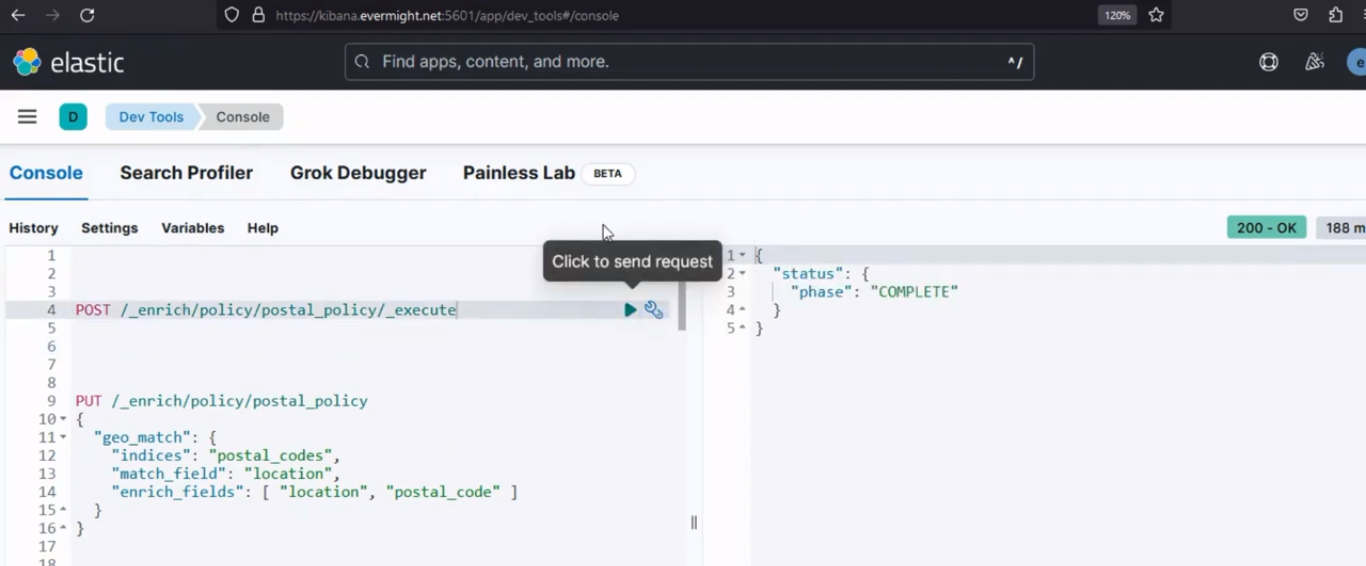 Resultado de la consola para el paso 3
Resultado de la consola para el paso 3
Para confirmar que el índice se enriqueció correctamente, vaya a Gestión de pilas > Gestión de índices, alternar el incluir índices ocultos Botón Activado, luego recargar índices.
Paso 4: Crear una canalización de ingestión [28:51]
Cree una canalización de ingesta y agregue un procesador de enriquecimiento:
PUT /_ingest/pipeline/postal_lookup
{
"processors": [
{
"enrich": {
"description": "Add 'geo_data' based on 'geo_location'",
"policy_name": "postal_policy",
"field": "geo_location",
"target_field": "geo_data",
"shape_relation": "INTERSECTS"
}
}
]
}
Utilice la siguiente canalización de ingesta para insertar un nuevo documento. El documento entrante debe incluir el campo especificado en su procesador de enriquecimiento.
PUT /users2/_doc/0?pipeline=postal_lookup
{
"first_name": "Mardy",
"last_name": "Brown",
"geo_location": "POINT (13.5 52.5)"
}
Después de ejecutarlo, debería producir un resultado similar a la imagen de abajo;
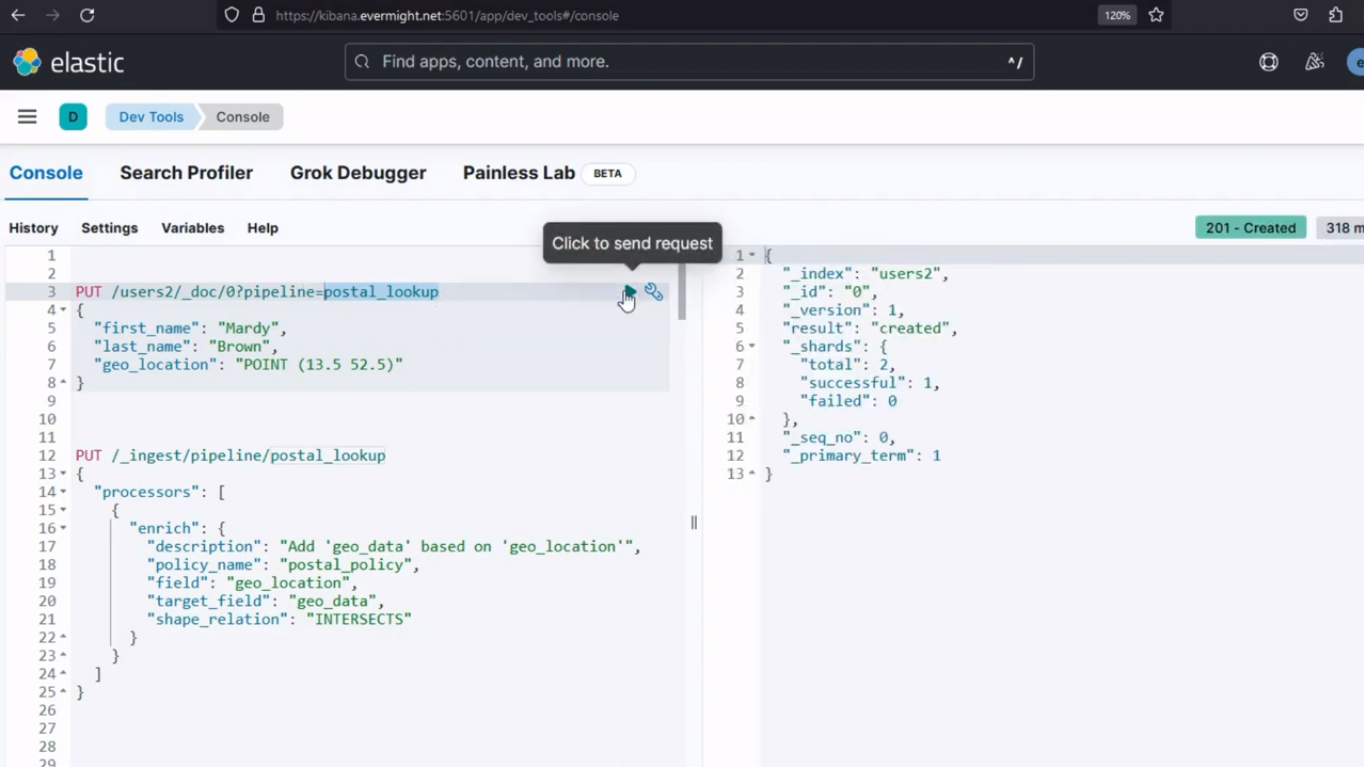 Resultado de la consola para el paso 4
Resultado de la consola para el paso 4
Y cuando realices una solicitud GET, verás el resultado:
GET /users2/_search
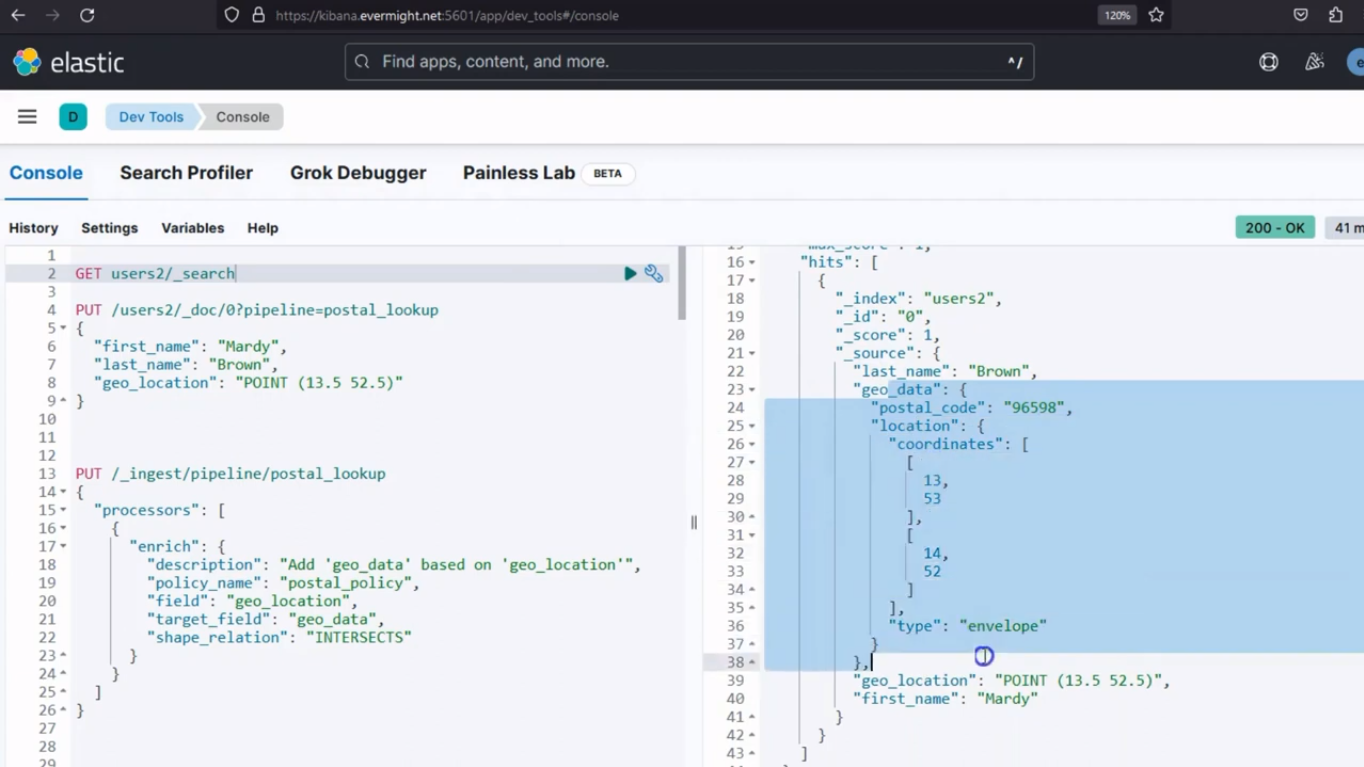 Resultado de la consola para documentos
Resultado de la consola para documentos